After years of studying Computer Science at university I've come to realize the simple yet powerful fact that digital technology is all about the processing of information encoded in data. What we're doing with technology, boiled down to its core, is creating ever more powerful machines that are able to generate, process, and manipulate ever increasing amounts of data in order to drive various activities and processes that require, as their complexity increases, ever more information.
Data are the raw contents of our computers memory. Data in and of itself is not that important: it is just a medium, a way to represent something else. Its this "something else", that is important: information.
And how could one grasp what is information?
Well, to really answer such question one could write more than an entire book – and, in fact, this has happened and will continue to happen – but in general I would say that information is anything your mind can possibly comprehend and more. Information is all about problems, decisions and the possible consequences of those decisions. Good information allows you to understand better whatever problem you are facing in whatever context you are currently situated in order to make a decision.
\[\big\downarrow\]
A decision made without any supporting information is simply a shot in the dark, nothing more than a bet. To make good, strategic decisions one has to work on getting the right kind of information. The difficulty of doing this depends of course on the particular problem at hand: sometimes its easy, sometimes its almost impossible, and most of the times is something in between those two extremes.
For the longest time, throughout most of history, humans have faced the problem known as information scarcity. That is, even just a few hundred years ago, information was mainly encoded in books, and in general it was very hard and expensive to get your hands on some good books which contained useful information.
Since the rise of digital technology, which made the duplication and distribution of digital information extremely easy, we now face a different problem: we are flooded with ever increasing amount of information, while our brain can only process a very limited amount of it. Everyday there are a crazy amount of articles to read, of tv-series and movies to watch, of books to study and so on. You get the idea.
In this blog post I want to discuss a powerful technique called web scraping.
If done well, web scraping can be used to solve the problem of dealing with ever increasing amount of information by extracting carefully from all the mess present in the Web, only the kind of information we're interested in. The power of this technique is that it can be automated, and so, after some initial work, we can keep getting our information without any additional hustle.
#HTML and the Web
The Web is probably one of the most tangible creation of the evolution of digital technology, since everyone uses it everyday. Yet if we consider the huge number of its users, only few of them understand even a little how it works under the hood. This article is clearly not the place to discuss such huge and deep topics, but still, to understand web scraping it's important to know how to think properly about the Web.
First of all, just what is the Web?
There are two key characteristics that any network posseses:
-
What kind of element it contains. These elements are called nodes.
-
How the different nodes are connected to eachothers. These connections are called edges.
By combining different nodes together with different edges, we get the intuitive notion of a network:
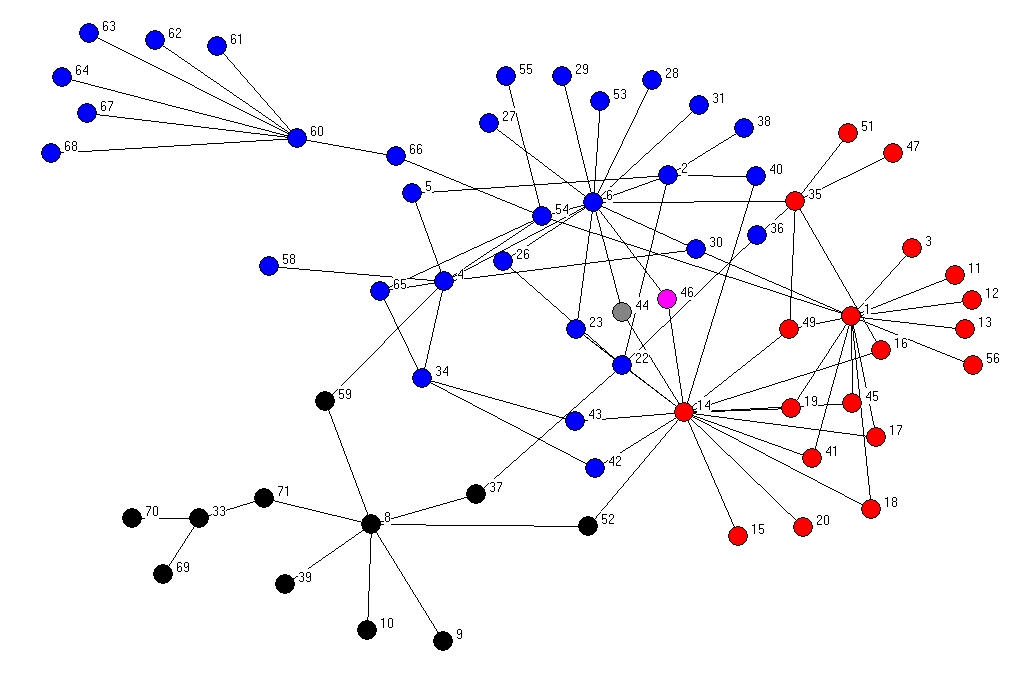
In the Web the majority of the nodes are html documents, and different nodes are connected to eachothers by links called hypertext references.
Whenever you go to google.com, your browser asks google web
servers to send back the page that contains the well known google
search form.
This page is a typical html page. But what is html?
HTML stands for HyperText Markup Language, and its the language
that is used to define the structure of the documents that can be
obtained in the web, that is, of html documents (or html
pages). But html does not only defines the structure of a
document, it also defines its contents.
To be able to read html, the main thing to understand is that an
html page is made up of various elements, and that each element is
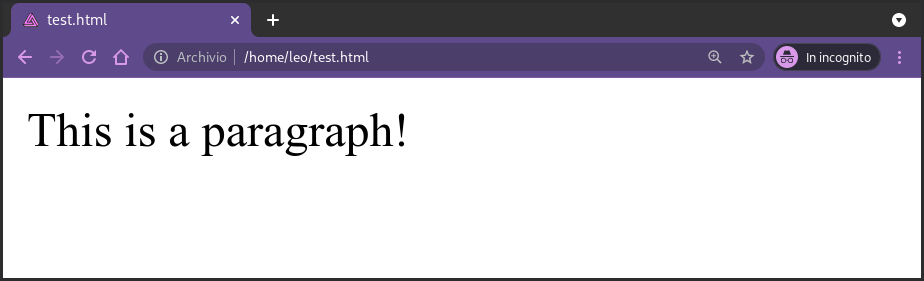
defined by certain tags. Consider for example the following
element, which in the html language represents a paragraph
<p> This is a paragraph! </p>
As we can see, the element is structured as follows: we have the
opening tag <p> which tells us we are entering a new paragraph,
then we have the content itself of the paragraph, and then we have
the closing tag </p> which means we're done with that paragraph and
we can move on to something else.
When the browser reads this html code, it interprets it and renders it on the page.
There are lots of different elements, each of which is used to characterize the purpose of a particular piece of data in a document.
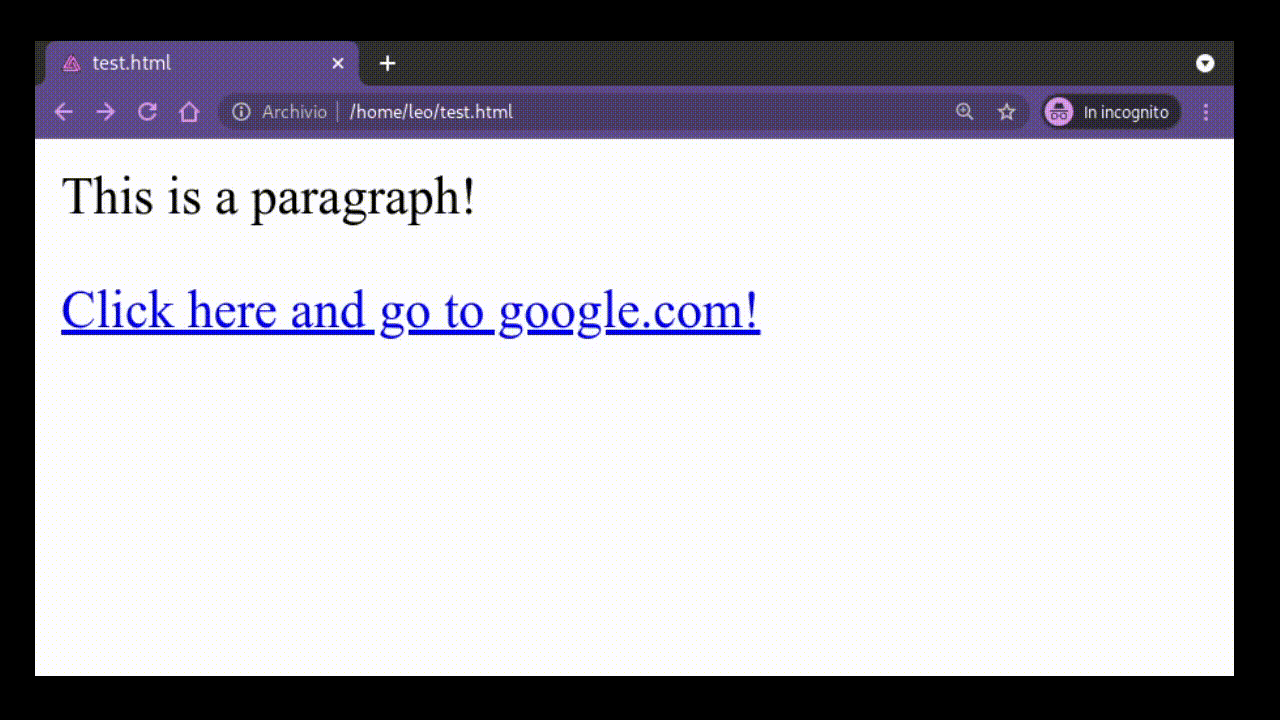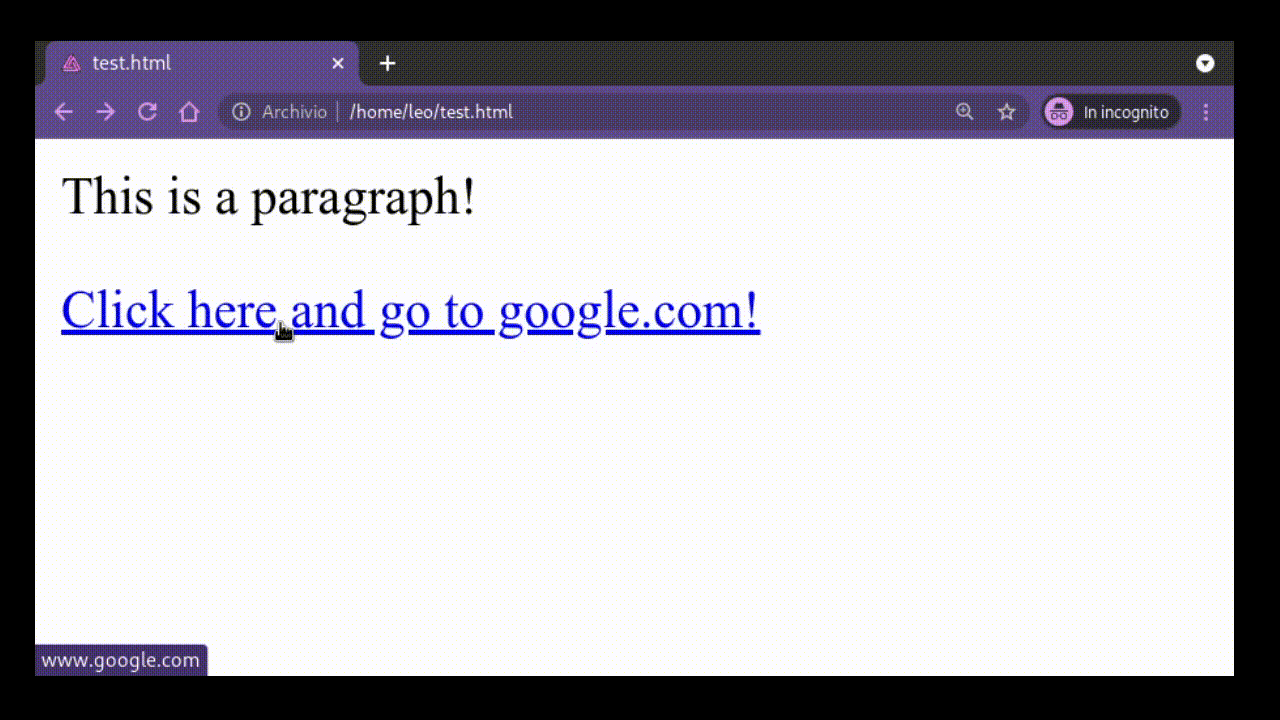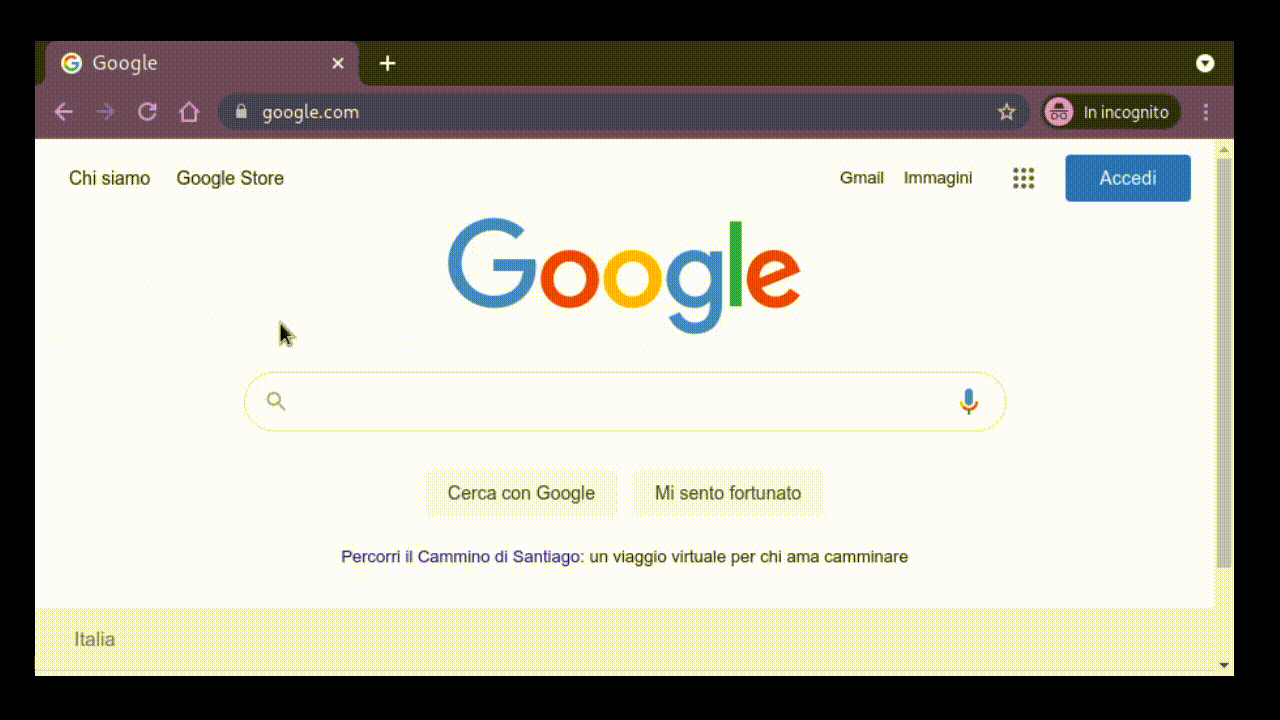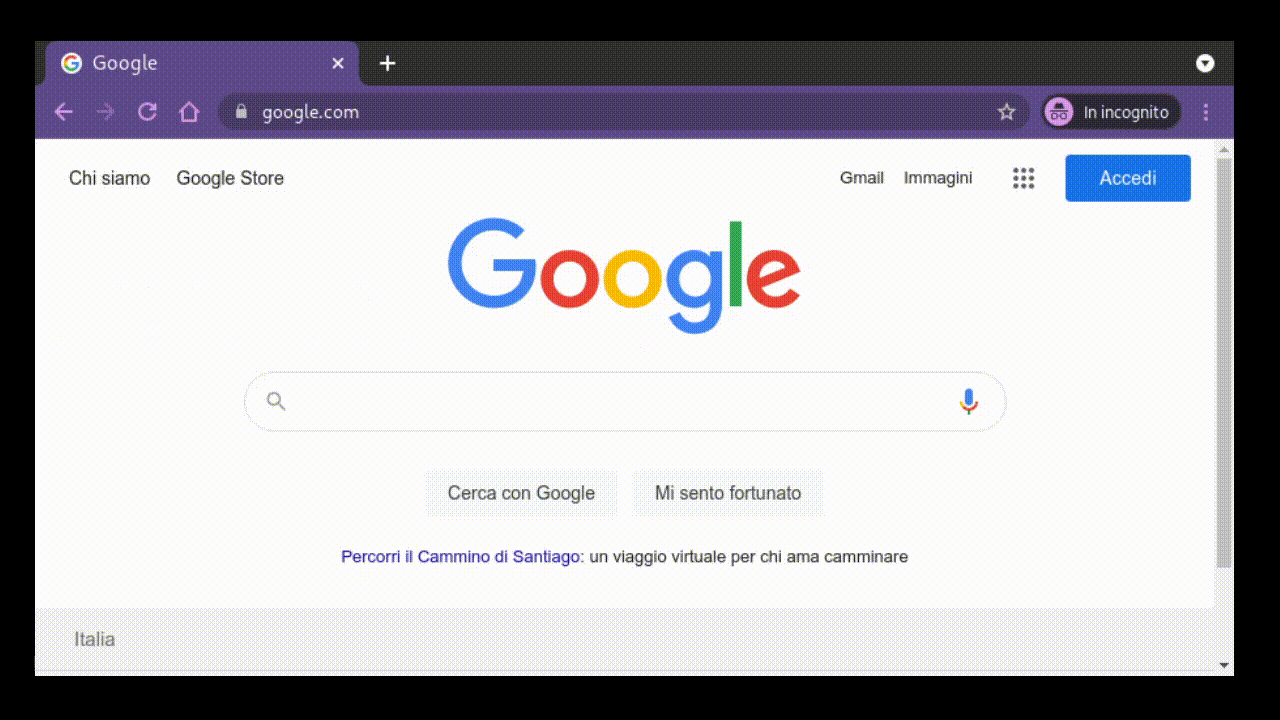
The most important element in html is, without a doubt, the anchor element. This element is used to link together different documents
with eachothers. It is the element which creates the edges in the
network of the web we've alread mentioned. The syntax of this
element is the following one
<a href="www.google.com"> Click here and go to google.com! </a>
as we can see, the tag for this element is the <a> tag. Notice also
another new thing: within the opening tag of the element we have an
attribute, which in this case is the href attribute, which contains
the "link" our browser will go to when a user clicks on the text
displayed within the tags.
Without entering into too much details about all the possible different tags, what is important to realize is that thanks to these tags the html language allows one to define both the different elements of the document as well as how they are related to one another. That is, by putting an element within another element, we can create a hierarchical structure.
Consider the following
<body>
<div id="content">
<h1> Headline level 1 </h1>
</div>
</body>
The body element is used to contain all the content of the
document, while the div element is a generic element with no
particular meaning, and it is used by front-end developers to
create complex graphical layouts by combining html with css.
Observation: css stands for Cascading Style Sheets, and its the language used to define the style for an html document. This blog post is not about css, because when doing web-scraping, we're not at all interested in this particular language.
However, just to show what it looks like, the following is a css snippet that sets the font-size of all text within the body element as well as the background color of the page.
body {
font-size: 30px;
background-color: black;
}
Returning now to the previous html snippet, what's important to
realize here is the fact that the h1 element is inserted within
the div element, which is itself inserted within the body
element. Its exactly this nesting of elements within other
elements that defines the structure of an html document.
Consider the following example of a full html document.
<!DOCTYPE html>
<head>
<title> Titolo Pagina </title>
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
</head>
<body>
<div id="content">
<h1> Headline level 1 </h1>
<p> This is a paragraph! </p>
<div id="footer">
<p class="author"><b>Author</b>: Leonardo Tamiano</p>
</div>
</div>
</body>
</html>
As we can see, the first element is the DOCTYPE element, and it
specifies that the document is an html document, as well as the
particular version of html used (yes, there are multiple versions
of html, each with its own pecularities). Then we have the head
element, which contains various metadata, that is, data that
encodes information regarding the other data in the document, such
as the title of the page, what kind of content there is in the
page, how it is encoded, and so on.
We can visualize the structure of this document using a tree, which
is a famous data structure used throughout computer science.
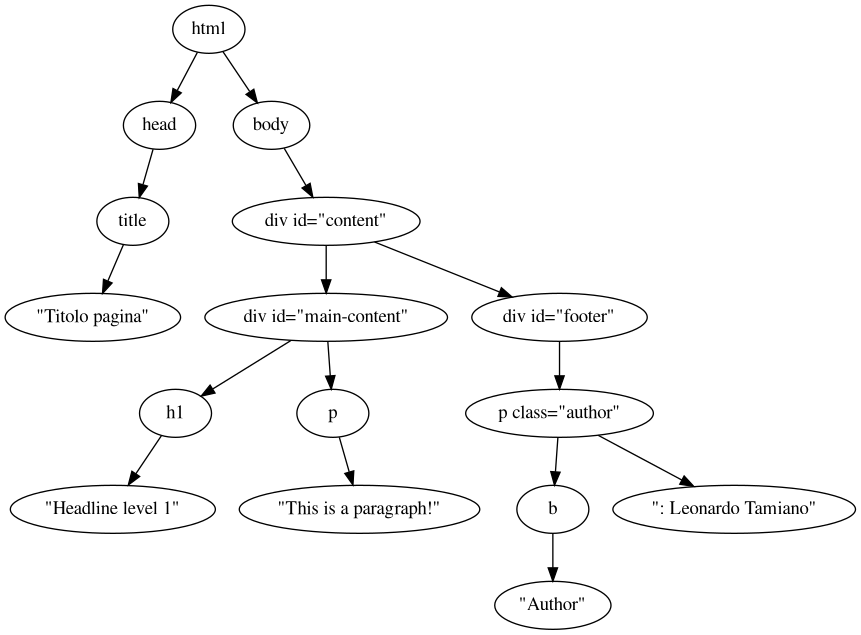
as we can see, this is another sort of "network", but here the nodes are the various elements of the html page, while the edges are used to represent which element contains which other element.
That is, consider the element body. There is an arrow from html to
body, and this arrow represents the fact that in the html document,
the html element (the one with the !DOCTYPE tag) contains the body
element. All the other edges encode the same kind of information
but for different elements.
Without going into too much detail, this structure is also called
the Document Object Model, in short DOM. By using the programming
language javascript one can modify the structure of the DOM to
create dynamic pages that change depending on the user action.
To recap briefly, when we download a web page, there are three main types of files we download (excluding all the images, sounds and other media types):
-
The
.htmlfiles, which define the structure of the content and the content itself that we're looking for. -
The
.cssfiles, which define how the content is displayed on the screen to the user. -
The
.jsfiles, which define how the structure of the content and the content itself changes depending on the user action.
When doing web scraping we're typically only interested in the
.html pages, since that's where the data we want is to be
found. Sometimes however the final html is obtained only after
executing a lot of javascript code. So sometimes just downloading
the html page is not enough: we also need to download the related
js code, and we have to execute it to get the final html page.
#Why would you do web scraping?
Now that we've briefly introduced what the Web is and how HTML is structured, before going into the technical details on how to do web scraping, I will now mention a couple of use-cases where knowing about web scraping could come in hand.
USE CASE #1: Display useful information in a different way
This use case is very real for me, because just recently I've had to implement it.
Currently I'm enrolled at the university of Tor Vergata studying Computer Science. As with everything in life, there are some good things and some bad things about this university. What bugs me the most however is that the official site of the course is just plain ugly and its not every efficient to use.
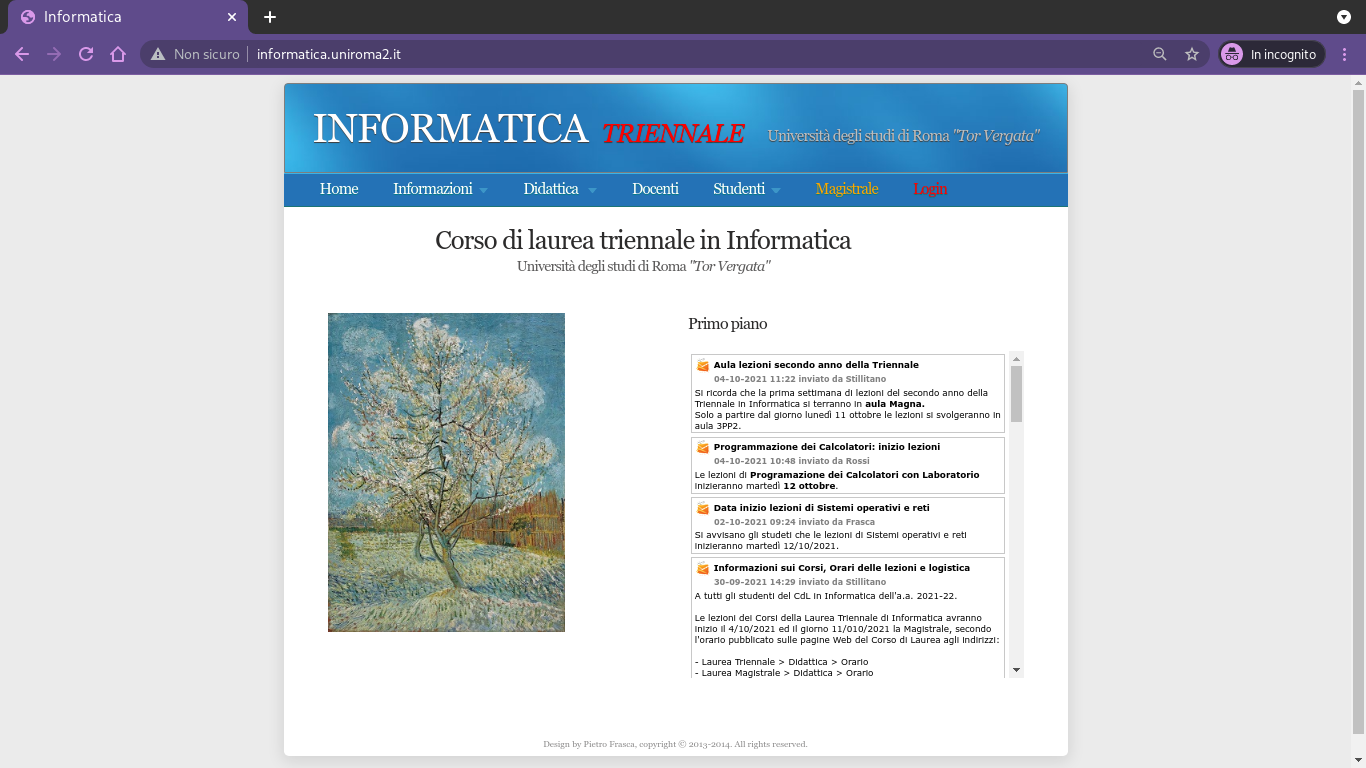
So, I asked myself: what can I do about it?
And that's where web-scraping came in hand, because what I did was:
-
I myself wrote a scraper which downloads all the web pages of the official site and extracts from these all the useful data that I need, such as exams and lectures dates, latest news, teachers contacts data, course data, and so on.
-
Then, working with a university friend of mine, we built (although I have to say it was he who did the heavy-lifting for the design and the style) a new web site which shows the same information but in a different style, which in our opinion is much cleaner and also easier to use.
The scraper can be found here: scraper.py, while our version of the site looks like this
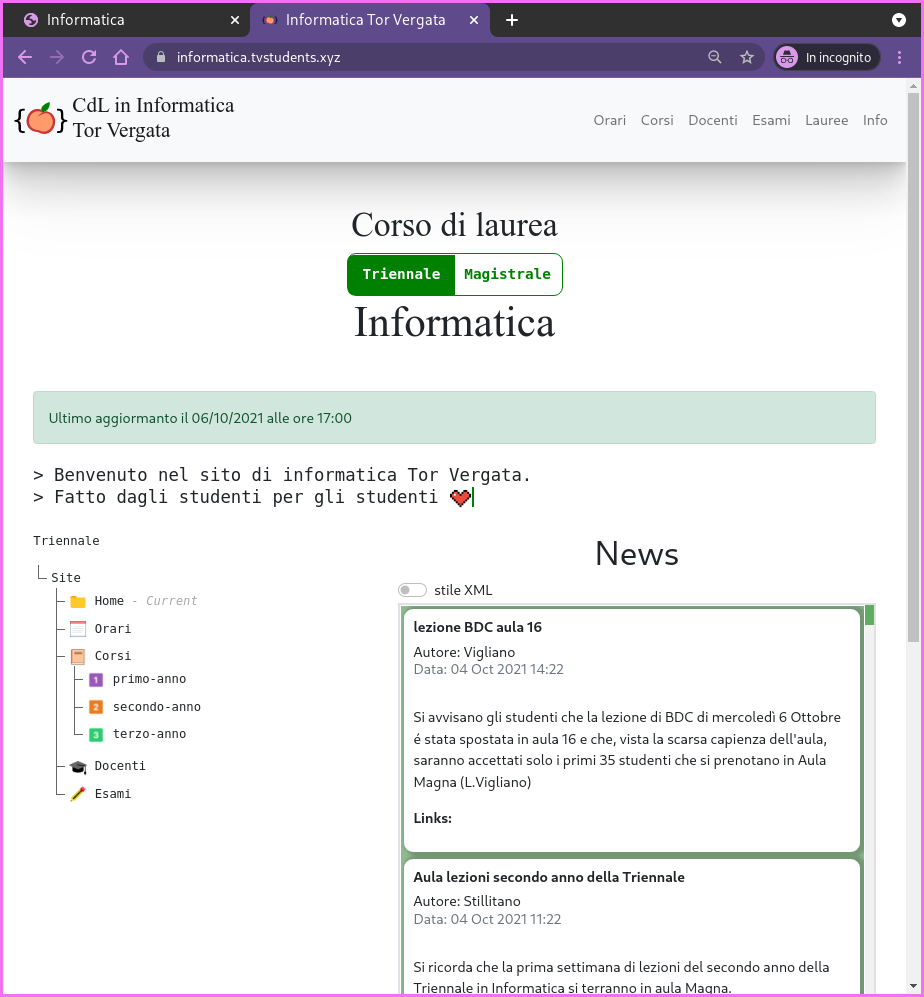
Now that we have the raw data we could offer a series of interesting services such as:
-
The ability to get notified when news are posted using RSS.
-
A log which shows the recent changes on the underlying data. This could be useful to know when a professor has uploaded new material.
-
An emailing service which alerts students when exam dates are set.
This are just a few of the endless services that one can offer with the raw data available. And to get the raw data, well, web scraping was necessary.
For those interested in the project just mentioned, you should check out the relative github repo: PinkPeachProject.
USE CASE #2: Show train tickets when reaching a certain price treshold
While the previous use case was very real, this one is not yet real enough for my taste. Still, I wanted it to mention either way because in the following weeks I might be working on something like this as a side-project.
Recently a friend of mine moved to Milano to study at Polimi for his master's degree in Computer Engineering. This means that in the following years from time to time I'll be taking trains to go and meet up with him.
Now, since train tickets cost money, and since the price of the tickets changes from time to time, I would like to write some python code that would periodically check the prices of the trains that go from Rome to Milan and back, and alert me when it finds ticket below a certain price threshold.
I'm not sure how practical this system would be, as I'm also not sure how much variation there is in train ticket prices (because if the variation is minimal, then the effort is probably not worth it). Still, it could be a cool idea to automate. If you ever implement something like this, or if you know something else that already does this, feel free to contact me :D
#How would you do web scraping?
Finally, after a lot of words, we can start to get our hands dirty.
I mean, if I did a good job at this point you understand a little bit better why web scraping can be very useful. Let us now tackle the remaing question: how do you actually do it?
As with everything in programming, our first tool to choose is the
programming language we want to use. In this blog-post we'll use
python3, because its a very flexible and powerful language.
But a language can be used to do many things, and each single
thing can be done in many different ways. This is also true for
web scraping. There are various libraries that allow you to do web
scraping in python. The one we'll use is called BeautifulSoup.
To download the library one can use pip, the package manager for
python
pip install beautifulsoup4
Since each library has particular naming conventions and ways of doing things, I always suggest to read the official documentation for a complete overview of what the library can do. Here I'll just give you enough pieces of code to get started.
If you're italian at this point I suggest you to watch the video I made on web scraping on my youtube channel:
Of course if you don't understand italian this might be hard for you, so just keep reading for the english version.
The html code we'll scrape is the following one, which is the same as the one shown before.
<!DOCTYPE html>
<head>
<title> Titolo Pagina </title>
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
</head>
<body>
<div id="content">
<h1> Headline level 1 </h1>
<p> This is a paragraph! </p>
<div id="footer">
<p class="author"><b>Author</b>: Leonardo Tamiano</p>
</div>
</div>
</body>
</html>
For now let us assume we have saved this page in a file named
web_page_example.html. Then we'll show how we can download it from
the web if we didn't already have it saved.
Since scraping is all about extracting useful information from the raw html data, to start off let's try to extract from the html file the name of the author, that is, the string "Leonardo Tamiano".
The usage of the library will be broken down in three steps:
-
Step 1 – Parsing the HTML file.
The first thing we'll always need to do is importing the
beautifulsouplibrary#!/usr/bin/env python3 from bs4 import BeautifulSoupafter that we have to read the html contents of the page we want to scrape. Since in this case we assume we already have the html document in a file, we can do a simple
openf = open("./web_page_example.html", "r") text = f.read()Finally, we have to parse the HTML file
soup = BeautifulSoup(text, 'html.parser')this call essentially puts in the
soupvariable the main data structure which is then used by the library to navigate the html document and extract data from it. -
Step 2 – Navigating the HTML file.
After we have parsed the file we can query the structure to navigate it.
Remember that tree I showed before? Well, now we'll navigate it. That is, starting from the root of the tree – the highest node, the one above every other node – we'll go to different nodes depending on our needs.
For example, we might be interested in going over all the
pelements, which can be done with# -- find all tags of the form <p> ... </p> paragraphs = soup.find_all("p")this method returns a list containing all the elements that matched the query. All elements contained in the returned list can then be used to search other elements depending on the document structure (that is, the tree I showed before).
In our particular case for example the
paragraphswill be a list of two elements: the first element is the one corresponding to the paragraph "This is a paragraph!", while the second paragraph is the one containing the information about the author.While from the first paragraph we cannot go further into the tree (such ending-nodes are called leaves), from the second paragraph we can go within the
belement, because in the tree thebelement is connected to the second paragraph.If no element is found, then an empty list is returned
[].if paragraphs: print("[INFO] - Found at least one paragraph :)") else: print("[INFO] - No paragraph was found :(")Notice however that in our particular case we are only interested in one paragraph: the paragraph element which has the class
author. We can add filters to our query by using adictionaryas follows# -- find all tags of the form <p class="author"> ... </div> author_p = soup.find("p", {"class": "author"})This time the method is
find, notfind_all, and thus it returns only the first element it finds that matches the query. If nothing is found, thenNoneis returned. This means that we can check if we found something withif author_p: print("[INFO] - A paragraph of class 'author' was found :)") else: print("[INFO] - NO paragraph of class 'author' was found :(")Other than with the find method we can also explore the html document with the dot (
.) syntax. For example if we doauthor_p.bwe get the first element associated with the<b>tag in the html document that is inside thepelement withclass="author". This gets us the same result as if we didauthor_p.find("b"). -
Step 3 – Extracting data from the HTML file.
Once we have obtained the element we're interested in, to extract the data we can do
# -- this gets us: "Leonardo Tamiano" name = author_p.textthis however only extract the textual data. If we want to extract both the text as well as the html tags, we have to do
# -- this gets us: "<b>Author</b>: Leonardo Tamiano" content = author_p.decode_contents()
This may not seem much at all, and in fact it isn't, but using
this library mainly reduces to this: doing calls to find and
find_all, and in general in understanding how to move within the
structure created by the library. Once we reach the interesting
elements, we can then do calls to text and decode_contents() to
extract the data.
In the meanwhile, all python facilities for strings and lists manipulation can be used for further processing.
In the snippet of code I showed, the html data was already saved as a file. How can we actually download it from the web? This step is very critical, and later we will come back to this point when discussing about the services offered by ScraperAPI.
Let us assume then that the previous html code is not anymore
saved on a file, but that it is served by a web server. To try on
your own machine, you can simply host the web server locally with
the following comand. Just be sure that the folder from where
you're executing this commands contains the web_page_example.html
file we want to download.
python3 -m http.server 1337
Now if we go to the url
http://localhost:1337/web_page_example.html our browser downloads
the html page we showed before.
To download a web page automatically we need a different python
library called requests. As always, the first thing to do is to
download it with pip
pip install requests
Once we have downloaded it, we can use it as follows
import requests
URL = "http://localhost:1337/web_page_example.html"
r = requests.get(URL)
if r.status_code != 200:
print("Could not download page!")
exit()
text = r.text
we can then give the variable text to the BeautifulSoup library as
showed before.
So, this is it for this brief showcase of the BeautifulSoup
library. If you want to see a real life example of using such
library, I would once again suggest you to go and read the scraper
I wrote for that university project: scraper.py.
For example, consider the get_teacher_list() function, which
downloads the contacts data of the various teachers. Since the
code is limited, I will simply paste it here and discuss it a
little bit.
The code is mainly divided into three parts:
-
In the first part we compute the proper
URL, and then we use therequestslibrary to download the web page containing the contacts data of the teachers.def get_teachers_list(self): """ Scarica le informazioni riguardanti i professori. """ # -- compute URL cdl_param = self.__cdl_param() URL_PARAMS = f"/f0?fid=30&srv=4&cdl={cdl_param}" URL = self.BASE_URL + URL_PARAMS r = requests.get(URL) if r.status_code != 200: print(f"[(WARNING) {self.degree}]: Could not download teachers data") exit() print(f"[{self.degree}]: Downloading teachers data") -
Then we open a file in which we will save all the data we extract from the web page.
# -- compute current scholar year in form 19-20, 20-21 scholar_year = get_current_school_year() file_path = f"{self.DATA_ROOT}/{scholar_year}/{self.directories['basic_dirs']['teachers']}/{self.directories['basic_dirs']['teachers']}.csv" with open(file_path, "w+") as out: # -- first row with metadata out.write("nome,qualifica,studio,telefono,mail,homepage,insegnamenti\n") -
Finally, we give the downloaded html page to the BeautifulSoup library, we search for a
tableelement, and we go over all the row (trelements) of the table. For each row we extract from the columns (tdelements) the various pieces of data, and we write all of it in the underlying filesoup = BeautifulSoup(r.text, 'html.parser') table = soup.find("table") rows = table.find_all("tr") for row in rows[1:]: cols = row.find_all("td") # -- extact data from columns nome = cols[0].a.decode_contents().strip() qualifica = cols[1].decode_contents().strip() studio = cols[2].decode_contents().strip() telefono = cols[3].decode_contents().strip() mail = cols[4].a.img['title'].strip() if cols[4].find("a") else "" homepage = cols[5].a['href'].strip() if cols[5].find("a") else "" # cv = "" insegnamenti = "" for ins in cols[7].find_all("a"): insegnamenti += ins.decode_contents().strip() + "-" insegnamenti = insegnamenti[:-1] # -- write to file out.write(f"{nome},{qualifica},{studio},{telefono},{mail},{homepage},{insegnamenti}\n")
Thus, after this has done executing, instead of having the
teachers data embedded in an html document with lots of other
tags, we will simply have a .csv file with only the data we're
interested in.
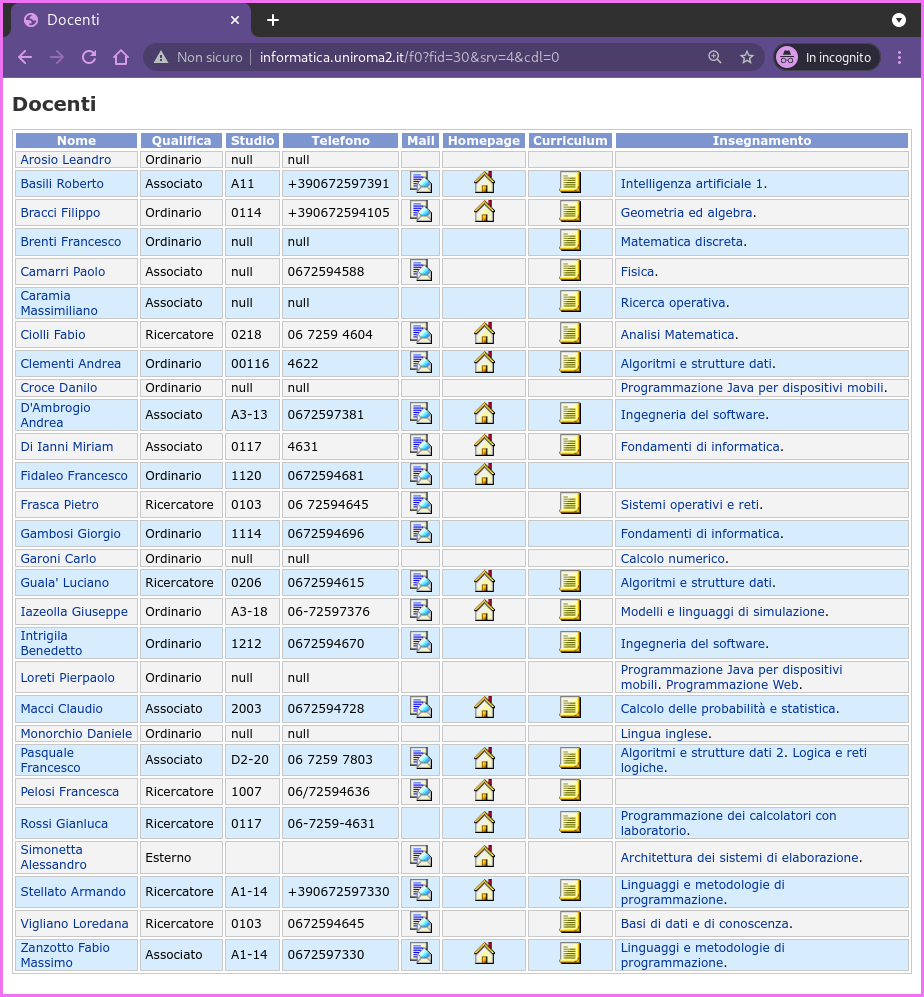
Graphically,
-
This is the view we get from the web browser.
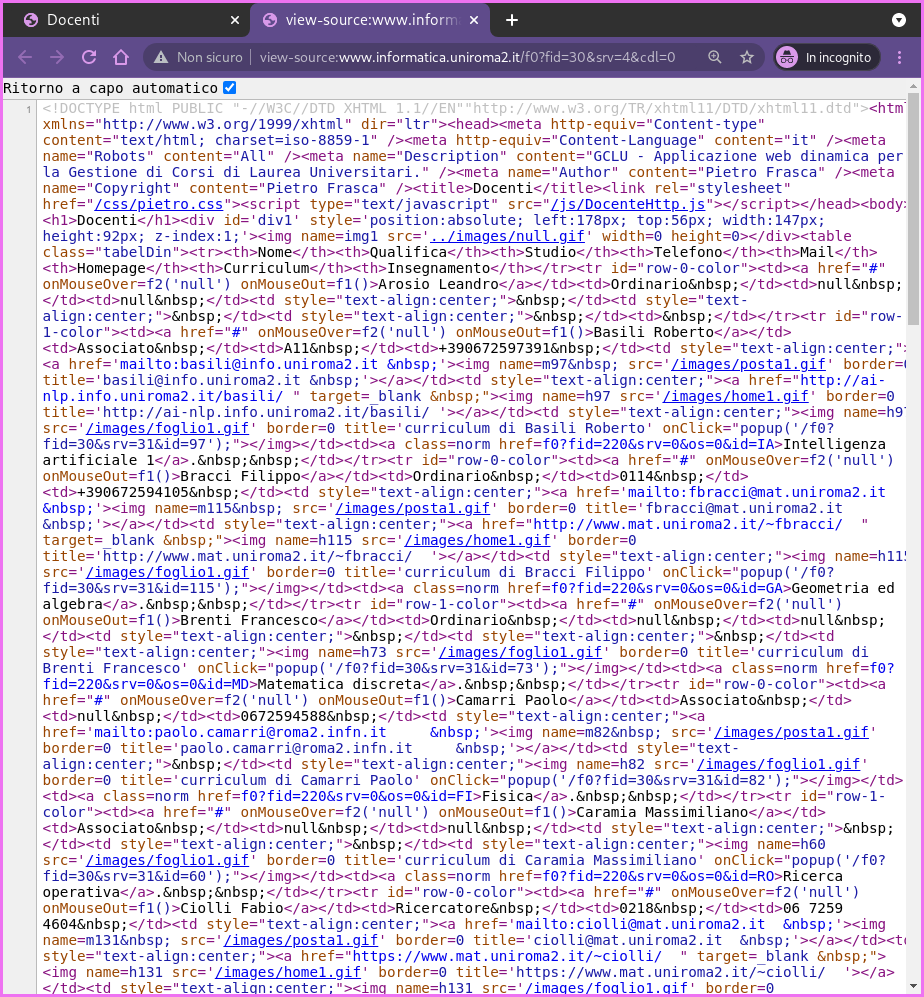
-
This instead is the underlying html code of that page, which contains the data we're interested in but its very hard to read.
-
Finally, this is the contents
.csvfile opened inEmacs(it would be the same in any other text editor) after the data has been scraped from the html document.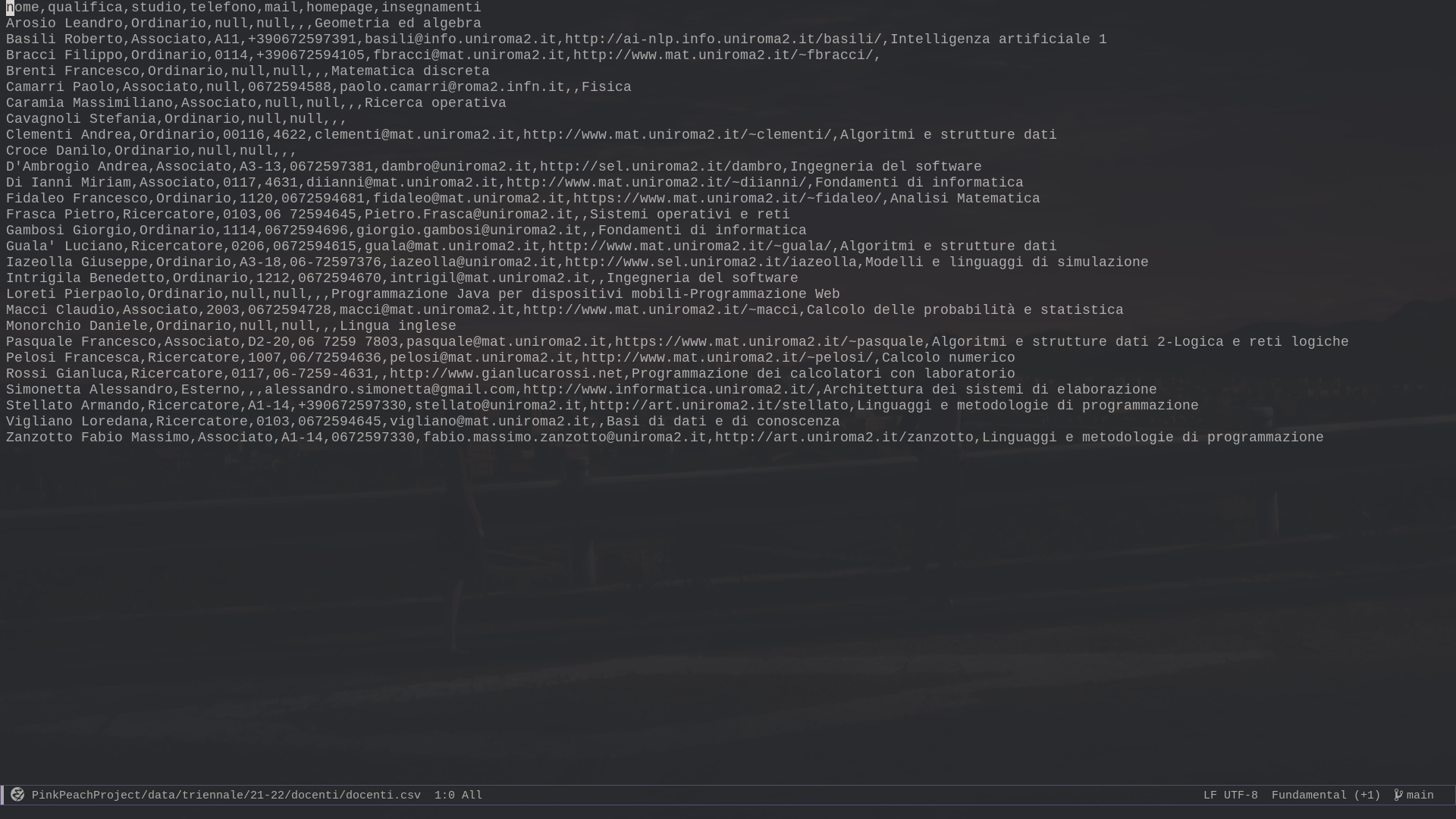
I hope this little example also gets across another point:
If a page is well structured, and if we can find the id and class
attributes values of the element we want to scrape, then scraping
the data becomes easy. If the page is a mess however it can be
quite hard to make sense of the structure and extract from it the
data we need.
So, this is it! I hope it was an interesting read, and if you want to give some feedback, well, feel free to write an email or a comment down below.
Have fun scraping and programming!