In the last 2-3 weeks I spent a significant amount of time developing a Linux device driver for a university project. The project was required by the Advanced Operating System course, which I followed last year, before all of this COVID-19 stuff happened. The course was extremely challenging and interesting, and I've definitely learnt a lot from it. Having just finished to write the driver (available here for those interested), I want to share something I found while looking at the internals of the linux kernel: a simple yet powerful implementation of doubly linked-lists. Before doing that though I want to discuss briefly what a doubly linked list is, as well as the first implementation I was shown of such data structure.
Feel free to skip to the part that interests you.
#What is a Data Structure?
Data structures are the daily bread of programmers. Programmers are, or at least should be, problem solvers, and to solve a problem one has to transform some input data into some output data according to a particular specification. There are various entities involved in this process, but at the end of the day problems are solved by algorithms. And algorithms - sequences of well-defined instructions - make use of various data structures to do their work. A "good" algorithm almost always makes use of a "good" data structure for the specific the problem at hand. This is why data structures are so important for programmers.
So, data structures are important, very important. But what do we mean exactly by data structure? It is hard to give a precise definition, but the intuitive idea is that typically a data structure has to have the following two components:
-
A description of the data being memorized. This description could be arbitrary complex, depending on the particular need of your algorithm, which, in turn, depends on the problem you're trying to solve. The only important thing is that this description has to specify, either implicitly or explicitly, both the data elements of interests as well as how they are laid out in memory.
Each language offers a specific way to write out this description: in C the construct
structis used. If we want to collect the data of a person, for example, like the name of the person, the age, and so on, we can use the following C-structstruct person { char *name; int age; }; -
While the description of the data is important to have, it is not the only thing we require of a data structure. We also have to define a certain set of operations to be performed on that data. These operations should clearly specify how such data has to be managed. The set of operations that a data structure defines is called an interface (or programming interface, or API, which stands for Application Programming Interface). To use properly a data structure you need to understand well its interface, and, conversely, when you write a data structure you should also document well how its interface ought to be used.
In our little example we could have an operation to set the age, and another one to print the age.
// sets the age of the structure pointed by p void person_set_age(struct person *p, int age) { p->age = age; } // prints the age of the structure pointed by p void print_age(struct person *p) { printf("Age of %s is: %d\n", p->name, p->age); }
So, to recap, a data structure is obtained by combining a description of the data of interest as well as the various operations that can be performed on that data. Let's now dig deeper into what we mean when we talk about a doubly-linked list.
#and a Doubly-Linked List?
Lists are among the simplest type of data structure. A list is
a very intuitive data structure to imagine, because it is
just a sequence of descriptions of data objects (like the one we
saw before with the struct syntax).

The thing that makes lists so usable is the fact that the
elements of the list do not have to sit near eachother in the
underlying memory. Remember, we are talking about programming,
and each piece of data we use in a program has to be stored
somewhere in a memory location. Leaving the intricacies of memory
addressing to another time, I'll just mention briefly another
data structure, called the array, which instead forces its
elements to reside on contiguous memory locations.

To actually allow this flexibility a list contains more than just the data required by the problem we're trying to solve: along side the "problem data", there is anoher type of data, which we'll call the "meta data" or simply metadata. In this case the metadata describes the internal structure of the list, and it should be mananged internally by the operations that modify the list (i.e. the operations exposed in the interface of the list). To implement a list we require a simple kind of metadata, because we only need to know the memory addresses of the various elements of the list. Variables that hold memory addresses are typically called pointers, because they "point to" a specific location in memory. Graphically pointers are represented as arrows.
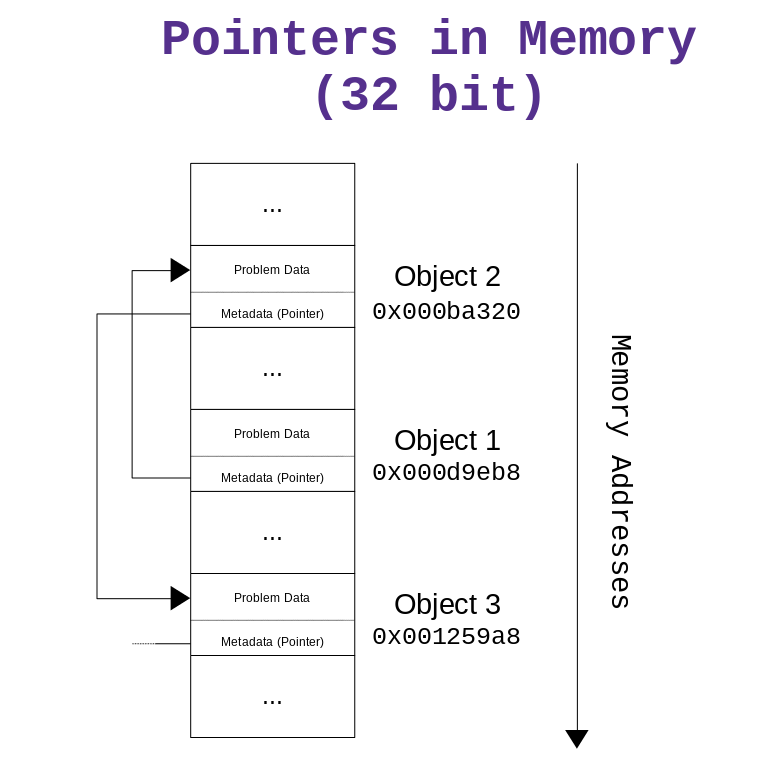
To fully implement a list you have to decide on what kind of metadata you want to insert in your list. For lists there are typically two different kinds of implementation, which are:
-
Singly-Linked List: In this implementation each element only knows its successor in the list. The only metadata required in this case is, for each element, a pointer which specifies the address of the next element. This is exactly the type of list shown in the previous image.
-
Doubly-Linked List: While a singly-linked list is the bare minimum necessary to have a working list of elements, sometimes it is extremely useful not only to store, for each element, the next element in the list, but also the previous element in the list. To do this we require two pointers for each element: a pointer that points to the next element, and one that points to the previous element.
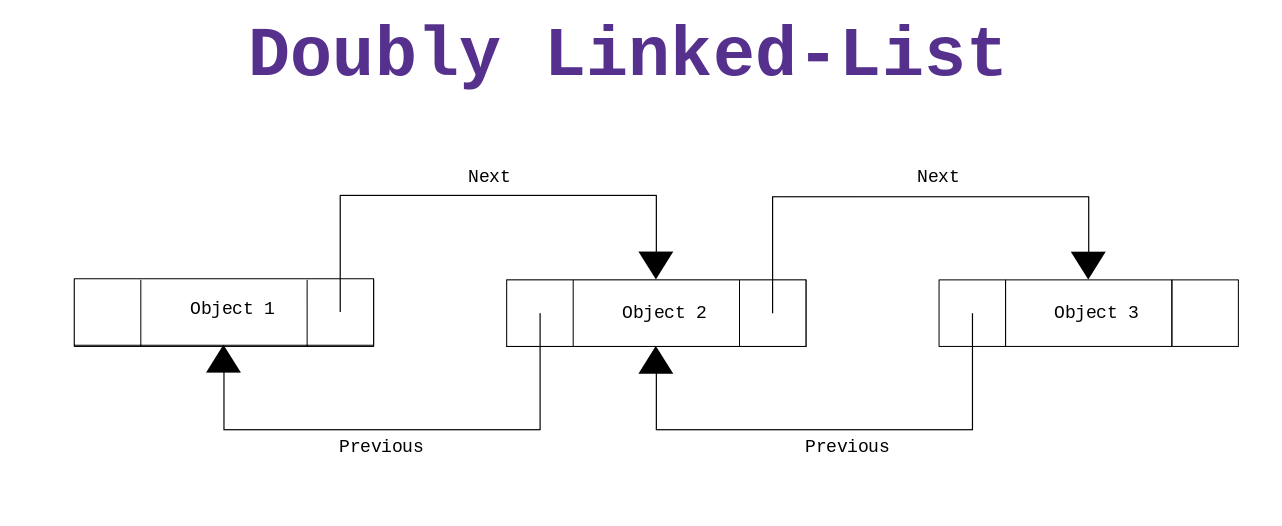
When implementing a doubly-linked list you can also decide wheter or not you want to connect the head and tail of the list with eachothers, creating a sort of cycle. This latter version of a doubly-linked list is also known as a cyclic list.
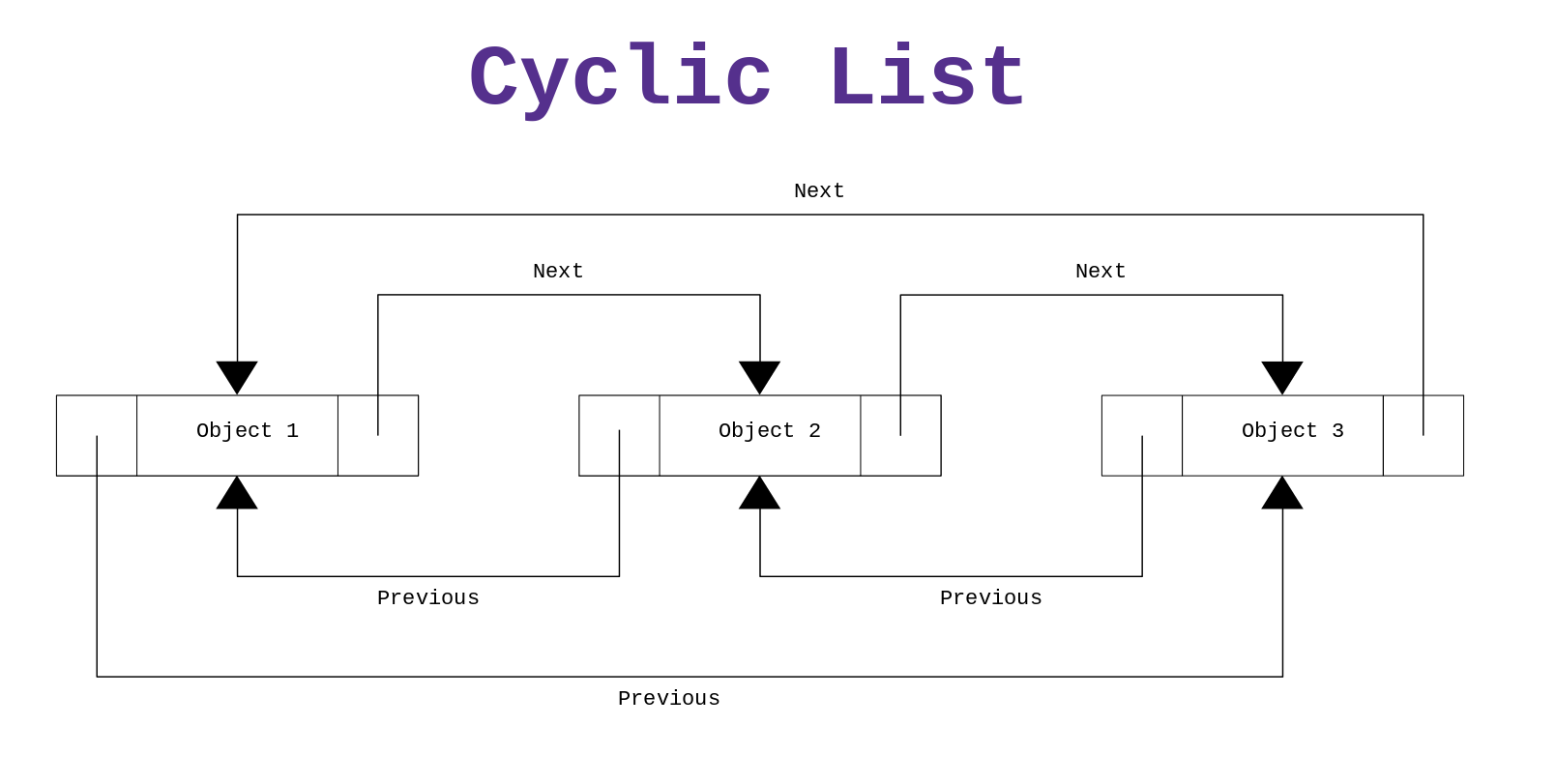
The operations you can perform on your data structure heavily depend on the kind of metadata you choose to memorize. This is why to decide what kind of metadata you want to insert in your structure it is crucial to understand what kind of operation you want to execute on your data: ideally the structure should be optimized so that the most frequent operations are also the fastest.
I'll now discuss a simple implementation of a doubly-linked list in C. The implementation I will be showing was the first one I ever encountered during my freshman year at university. For this reason it has a bunch of problems when trying to apply it to real-world scenarios. These problems will be discussed at the end of the next section.
#The CS 101's Way
When you are first introduced to lists, especially if done in a C-like environment, you'll typically be presented with a variation of the following struct
typedef struct node {
int key;
struct node *prev, *next;
} node;
As we can see, the struct contains an integer and two pointers (in
C pointers are defined with the keyword *), each of which points
to another object data of the same type, in our case a struct node. These pointers are the metadata I was talking about: they
are used to understand, given any element of the list, what is the
corresponding next/previous element of the list.
// when using the actual structure
struct node n = ...
n.key; // access its key value
n.prev; // access its prev element
n.next; // access its next element
// when using a pointer to the structure
struct node *p = ...
p->key; // access its key value
p->prev; // access its prev element
p->next; // access its next element
NOTE: In the definition the typedef keyword is added there as
syntax sugar to enable to write node instead of struct node to
refer to the structure type.
#Implementation
To use such structure we obviously need to define a bunch of operations that work on the list. To make it reasonably short, we'll just discuss the following three operations. For the complete implementation you can look into my archive (basic_list.c).
// initializes list
node *list_init(int k);
// adds element on top of list
node *list_add_head(node *head, int k);
// deletes element from top of list
node *list_del_head(node *head);
// returns first element from list with specified key
node *list_elem_key(node *head, int key);
Let us start then:
- list_init(): This function deals with the initialization of the
list by creating the first node with the key passed as
input. Notice the usage of the function malloc() to allocate
memory in the heap. Also, since the first element has no
previous/next element, we can both pointers to NULL.
node *list_init(int k) { node *new_head; new_head = malloc(sizeof(node)); if(!new_head) { fprintf(stderr, "Failed to allocate memory during list_init()\n"); return NULL; } new_head->key = k; new_head->prev = NULL; new_head->next = NULL; return new_head; }
-
list_add_head(): This function inserts a new element with the key given as input before the first element of the list passed as the first argument. The previous list is thus modified and a pointer to the new head of the list is returned.
node *list_add_head(node *head, int new_key) { node *new_head; new_head = malloc(sizeof(node)); if(!new_head) { fprintf(stderr, "Failed to allocate memory during list_add_head()\n"); return head; } // initialize new elem new_head->key = new_key; new_head->next = head; new_head->prev = NULL; if(head) { // update head's previous pointer to new elem head->prev = new_head; } return new_head; }As we can see we, once again we first allocate new memory using the malloc() function, and then initialize the data and metadata of the new element, as well as update the metadata of the first element of the list we want to modify, but only if that element exists.
-
list_del_head() This function deletes the first element of a list and returns the new head of the list.
node *list_del_head(node *head) { node *new_head; if(!head) { return NULL; } new_head = head->next; if(new_head) { new_head->prev = NULL; } // deallocate mem for old head free(head); return new_head; }Notice the
new_head->prev = NULLinstruction, which modifies the metadata associated with the new head of the list, signaling that it does not have a previous element anymore.
-
list_elem_key(): This function iterates the list and returns the first element of the list who's key value is the same as the one passed as input.
node *list_elem_key(node *head, int key) { node *elem; if(!head) { return NULL; } for(elem = head; elem != NULL; elem = elem->next) { if(elem->key == key) { break; } } return elem; }This function is also useful for understand how we are able to iterate over all the elements of the list: we start from the head of the list, and we access all the other elements by using the
nextfield of the element withelem->next(elemis a pointer). Of course the loop has to finish as soon as we find an element with the given key, or when the list is over. In this second case the code returnsNULL.
#Usage
The actual usage of the code we have just shown looks something like the following
node *l, *s;
l = list_init(5);
// now list l is { 5 }
l = list_add_head(l, 7);
// now list l is { 7 5 }
l = list_add_head(l, 4);
// now list l is { 4 7 5 }
list_print(l); // prints { 4 7 5}
s = list_elem_key(l, 7);
printf("%d\n", s->key); // prints 7
#Possible Improvements
The implementation we have just shown is simple and I think its
reasonably good for teaching purposes because it introduces the
uninitiated to things like memory allocation (i.e. the usage of
malloc()), as well as the explictly usage of pointers. When you
are beginning to learn programming its actually quite hard to
implement a structure like this without making any mistakes. And
when you deal with pointers there's a high-cost for any mistake
you make. Only God knows (assuming something like God is an
entity that actually exists outside our own mind) how many hours
have been wasted trying to debug segmentation-fault errors casued
by the invalid usage of pointers; not to mention the amount of
vulnerabilities, exploits, and thus the damage caused by such
mistakes done on a professional level.
So, as a first introduction to list, the approach I showed is definitely a good one. Still, its important to know that things can be done in a much better way. What could be improved upon in our implementation? A few things come to mind:
-
First and most importantly of all, the list we have implemented can only contain integers. This is because in the struct we have hard-coded a single int and nothing else. What can we do if instead we want a list whose elements are characters? Or floating point numbers? Or data with a more complex structure, like the
struct personwe have defined before? With our implementation we can't deal with all of these cases, and thus we have to find a better way of defining the list so that it is more flexible in regards to the type of "problem data" it can hold. -
Another point that could be improved is in the way we manage the metadata of our list. In the implementation just showcased we set the prev field of the head (the first element of our list) and the next field of the tail (the last element of our list) to
NULL. While this is not an error per-se, we could make the list even more flexible to use if we instead connect the head with the tail. This simple change would enable the list to be used as a FIFO queue, which is a data structure where new elements can be added and extracted in a First-In-First-Out order, meaning that the first element that gets added is also the first one that gets extracted, the second element that gets added is the second one that gets extracted, and so on for all the elements.With our own implementation we can only support a stack, where the first element extracted is the last one added.
-
To finish off, another thing which I personally do not like is the fact that our implementation requires us to update the head pointer of the list everytime we insert a new element. Consider the following code
node *l; l = list_init(5); l = list_add_head(l, 7); // list is { 7 5 } // now l points to the head of the list printf("%d\n", l->key); // prints 7If we forget to get the return value of list_add_head() we could mess up the structure of the list if we used
lthinking it was the head, because in such caselwould not point to the head, but rather to the second element of the list.node *l; l = list_init(5); list_add_head(l, 7); // list is { 7 5 } // now l points to the second element of the list printf("%d\n", l->key); // prints 5
So, while this implementation is a good starting step in the process of understanding data structures - and in particular doubly linked list - it is far from perfect. Having had to implement a FIFO queue inside the linux kernel for a university project, I started to look into how the kernel manages doubly-linked list. What I found was a very simple and strong implementation of such data structure, which I will partially showcase in the following section.
#The Linux Kernel's way
Writing kernel code is hard. Writing good kernel code is extremely hard.
{{< figure position="center" src="/images/kernel_linked_list/one_does_not.jpg">}}
This difficulty comes from the fact that the kernel is the software that stands in between the hardware and the more traditional applications we use. Browsers, Word Processors, Spreadsheets, Image Processors... all these applications (and many, many more) require the usage of hardware resources such as CPU-time, RAM-memory and disk-space. The purpose of an operating system is to manage the hardware resources of a computer in order to enable these processes to operate in the most efficient and secure way, which in turn enables us to do our everyday work, whatever that may be. The core part of an operating system, the one we don't see and yet does all the work, is called the kernel. The kernel is used for many things, such as
-
Managing all the hardware resources such as CPU-time and RAM-memory needed to execute our programs.
-
Creating the main software abstraction that can then be used by our programs to interface with hardware devices.
-
Enforcing the correct protection mechanisms so that different processes do not mingle with one-another in non-intended and nefarious ways.
All of this requires a lot of machine-dependent code as well as an incredible amount of complex software abstractions. It is no wonder then that the kernel has a stupid amount of lines of code.
Having said that, there's still hope of getting something out of all this mess. Indeed, even if writing proper kernel code is extremely hard, reading it is less so. Don't get me wrong: understanding a significant portion of it may still be extremely challenging, maybe even impossible for us mere mortals, but among all the complexities and all the abstractions, there are some islands of clarity: pieces of code which are simple, self-contained, and easily understandable.
This appears to be the case with the way the linux kernel
implements doubly-linked list. The file of interest can be found
at include/kernel/list.h either from pulling the official github
repo or, for a quick online peek, by using the elixir cross
referencer. Since the actual kernel code contains a lot of
abstractions, what I will be showcasing here instead is a
simplification of the code so that it works at the user-space
level (that is, like a typical C file). I've really just removed a
bunch of macros which deal with aspects that only matter to the
kernel. The core implementation of the list structure remains
unchanged.
#struct list_head
The actual data type used for the list implementation is defined
in another file named include/linux/types.h and is the following
one
struct list_head {
struct list_head *next, *prev;
};
When I saw that definition for the first time I immediately thought: "wait a sec, but in this struct I see only pointers, that is, only the metadata. Where is the actual data that the list has to maintain?". This is probably one of the coolest thing I like about the way the kernel implements linked lists: instead of combining the metadata and the data inside the same struct, like we did before, the idea is to embed the list struct, which only contains the metadata, inside a more general struct that actually contains the application data.
To clarify my point I'll just show you the two different way to
implement a list of persons using the struct Person we have
previously defined:
-
By combining the data with the metadata in a single struct: this is the way we have used previously and it looks like this
struct person { char *name; int age; struct person *next, *prev; }; -
By embedding the metadata inside a bigger struct: this instead is the way of the linux kernel, and it is defined as follows
struct person { char *name; int age; struct list_head list; };
The kernel APIs to manage lists take as arguments pointers of the
type struct list_head and can do various things on the list, such
as adding new elements, deleting old elements, and so on. But
before delving into that, let us now discuss a key point: ok,
suppose I have a list of persons implemented in the 2nd way, that
is by embedding the metadata within the application data, and
suppose that I manage to get a pointer to a struct list_head that
I know belongs to that list. How do I get hold to the actual
application data of that particular element of the list?
Paraphrasing: how do I go from the struct list_head poiner to the
struct person pointer to get, for example, the age of the person?
This is done by the macro list_entry().
#list_entry()
This macro allows one to get a reference to the "bigger" struct
using a pointer of any element situated within the "bigger"
struct. In the case of lists, the element is the struct list_head
and It is used as follows
// suppose we have a pointer to a person struct
struct Person *p1 = ...;
// let us reference the list element inside of it
struct list_head *head = &p1->list;
// now, starting from the poiner of the list element, we'll get
// back the address of the person struct indirectly using the
// list_entry() macro
struct Person *p = list_entry(head, struct Person, list);
pritnf("%p\n", p1); // prints 0x7ffd114bec60
pritnf("%p\n", p); // prints 0x7ffd114bec60
// the addresses are the same!
Graphically we have the following scheme
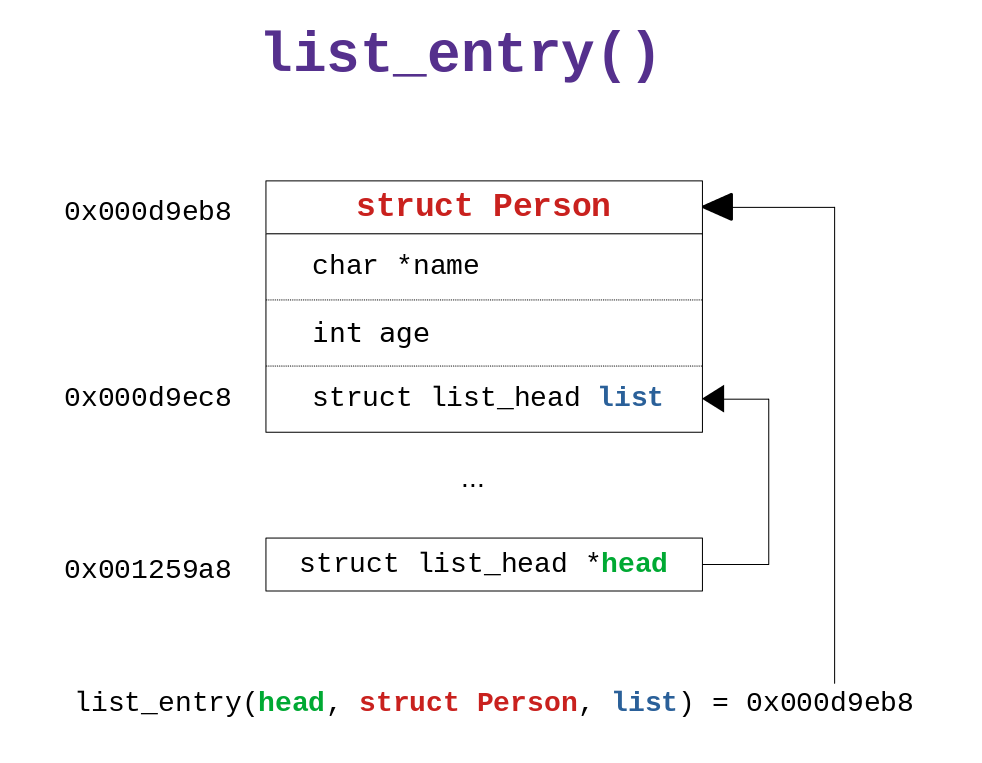
To understand how this macro works you simply need to look at its
definition in the source code (the list.h file mentioned before),
to find the following
/**
* list_entry - get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_head within the struct.
*/
#define list_entry(ptr, type, member) container_of(ptr, type, member)
As we can see, the list_entry() simply calls the container_of()
macro, which is itself defined in another file, namely
include/linux/kernel.h, and without burdering you with even more
details, I'll just get to the point and trim it to its core
components
/**
* container_of - cast a member of a structure out to the containing structure
* @ptr: the pointer to the member.
* @type: the type of the container struct this is embedded in.
* @member: the name of the member within the struct.
*
* NOTE: In the kernel code there is a call to BUILD_BUG_ON_MSG()
* for checking if the pointer type missmath.
*/
#define container_of(ptr, type, member) ({ \
void *__mptr = (void *)(ptr); \
((type *)(__mptr - __builtin_offsetof(type, member))); })
As we can see this macro internally uses __builtin_offsetof(),
which returns the offset of the variabled named member inside the
struct type. The offset of a field inside a struct is the value
that is needed to add to the first address allocated for the
struct to reach the address of the particular field of
interest. You can experiment with it as follows
struct Person p;
// returns 0
printf("offset of name in struct Person is %lu\n",
__builtin_offsetof(struct Person, name));
// returns 8
printf("offset of age in struct Person is %lu\n",
__builtin_offsetof(struct Person, age));
// returns 16
printf("offset of list in struct Person is %lu\n",
__builtin_offsetof(struct Person, list));
As we can see see the elements in memory are not allocated one
after the other: age for example is an int, which makes it a \(4\)
byte value, but to go from age to list we move \(8\) bytes. This
extra space is called padding, and it is inserted by the compiler
for optimization purposes.
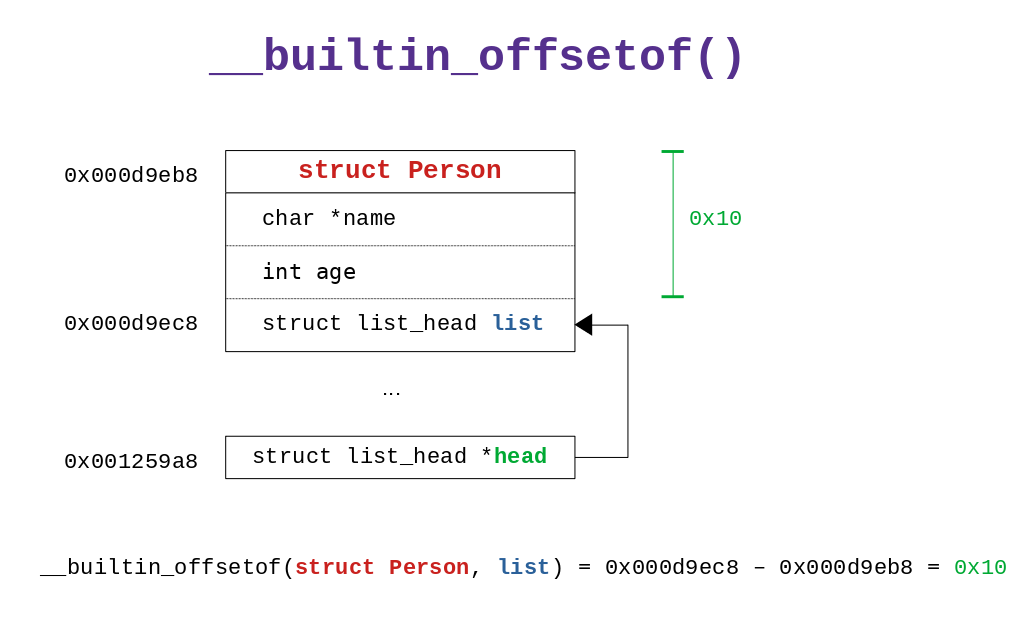
Putting it all together we get the following
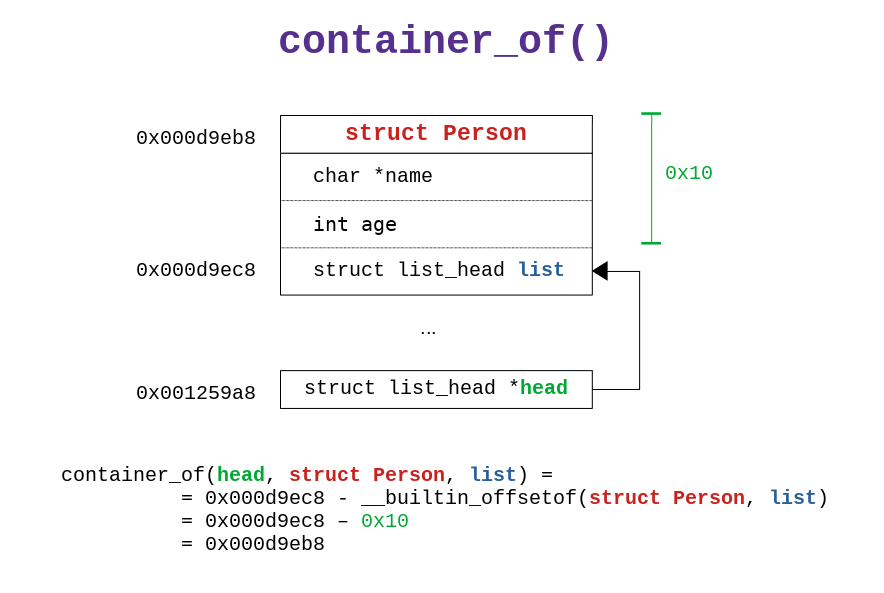
#Implementation
The actually implementation of the list is very straight forward, mainly because it is assumed in the design of the structure that the job of allocating/deallocating memory is done on the part of the user of the list. Here I'll just describe a bunch of functions, the rest you can look up in my archive (kernel_list.h).
-
INIT_LIST_HEAD(): This is used to initialize the list.
static inline void INIT_LIST_HEAD(struct list_head *list) { list->next = list; list->prev = list; };Notice how both the
nextandprevfield of the element are set. This is done to implement a cyclic list, which is a nice thing, because it allows us to add elements either in the head of the list or the in the tail of the list with \(O(1)\) cost.
-
list_add() and list_add_tail(): both these functions add a new element to the list, but while the first one adds the element as the new head of the list, the second one adds the element as the new tail of the list.
/** * list_add - add a new entry * @new: new entry to be added * @head: list head to add it after * * Insert a new entry after the specified head. * This is good for implementing stacks. */ static inline void list_add(struct list_head *new_node, struct list_head *head) { __list_add(new_node, head, head->next); } /** * list_add_tail - add a new entry * @new: new entry to be added * @head: list head to add it before * * Insert a new entry before the specified head. * This is useful for implementing queues. */ static inline void list_add_tail(struct list_head *new_node, struct list_head *head) { __list_add(new_node, head->prev, head); }The structure for both of these calls is the same: the subroutine __list_add() first checks the validity of the operation to be done, and if its legit it is then carried forward.
static inline void __list_add(struct list_head *new_node, struct list_head *prev, struct list_head *next) { if (!__list_add_valid(new_node, prev, next)) return; next->prev = new_node; new_node->next = next; new_node->prev = prev; // In the kernel this is a WRITE_ONCE() operation prev->next = new_node; }Finally, the function __list_add_valid() always returns true (that is, 1) for performance reasons, unless the config option CONFIG_DEBUG_LIST is explicitly enabled, in which case the proper checks are done.
// defined like this when CONFIG_DEBUG_LIST is NOT used for // performance reasons static inline int __list_add_valid(struct list_head *new_node, struct list_head *prev, struct list_head *next) { return 1; }
-
list_for_each(): This a useful macro that sets a for loop to iterate the elements of the list.
/** * list_for_each - iterate over a list * @pos: the &struct list_head to use as a loop cursor. * @head: the head for your list. */ #define list_for_each(pos, head) \ for (pos = (head)->next; pos != (head); pos = pos->next)As we can see from the loop, it begins not with the first element (the
ħead), but rather with the next element ((head)->next).
#FIFO Queue
If you are interested in seeing a proper usage of these APIs you can look at the following files in which show a simple implementation of a FIFO queue:
-
queue.h, contains the main struct for the queue as well as the function declarations, that is, the interface of the queue.
-
queue.c, contains the main implementation of the queue.
Otherwise look here for a more toy example: kernel_list_usage.c.