Few months ago I started my PhD in applied cryptography. I'm still in a very confused position as to the specific research that I will focus on in the future. Having said that, given that during my master's thesis I've studied and implemented a few scenarios involving famous cryptographic attacks that were done to the TLS protocol, that is where I'm starting off: trying to understand as many details as possible about the TLS protocol and, in particular, about the various implementation of such protocol in the wild.
As an excuse to review what I learn and study, I want to write more about the TLS protocol. Initially I will write very basic things, because everything starts from a simple base, and then, in the future, I also hope to cover some of the more complex and detailed ideas around TLS. To start off, this blog post will introduce the main ideas behind TLS, what it is, and why it was needed in the first place.
I hope it is an enjoyable read!
#What is TLS?
First things first, TLS is an acronym which stands for "Transport Layer Security". If one had to give the most brief description of TLS, it would be necessary to mention that TLS is a network protocol. There are many network protocols out there. Internet, and the web in particular, are possible only because various network protocols come together in order to grant various services.
When learning network systems, one is often presented with the famous ISO/OSI model, which is an abstraction that wants to describe how the communication between two computers can happen. It is a very useful model, because it breaks down communication in a series of layers, where each layer is responsible for only a specific aspect of the communication.
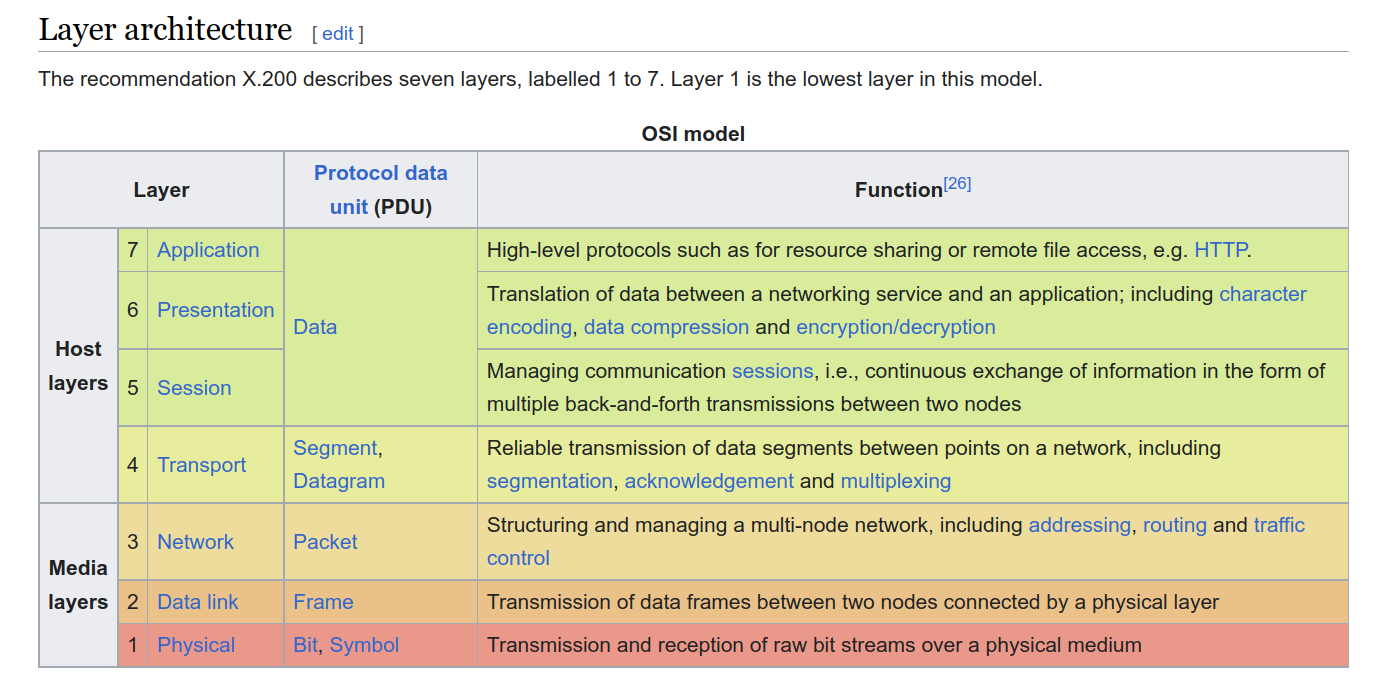
While the standard ISO/OSI model has about \(7\) different layers, the one that was actually implemented in real networks had about only \(4\) different layers. When two applications need to communicate with eachothers, these layers are all activated one after the other, as is shown below
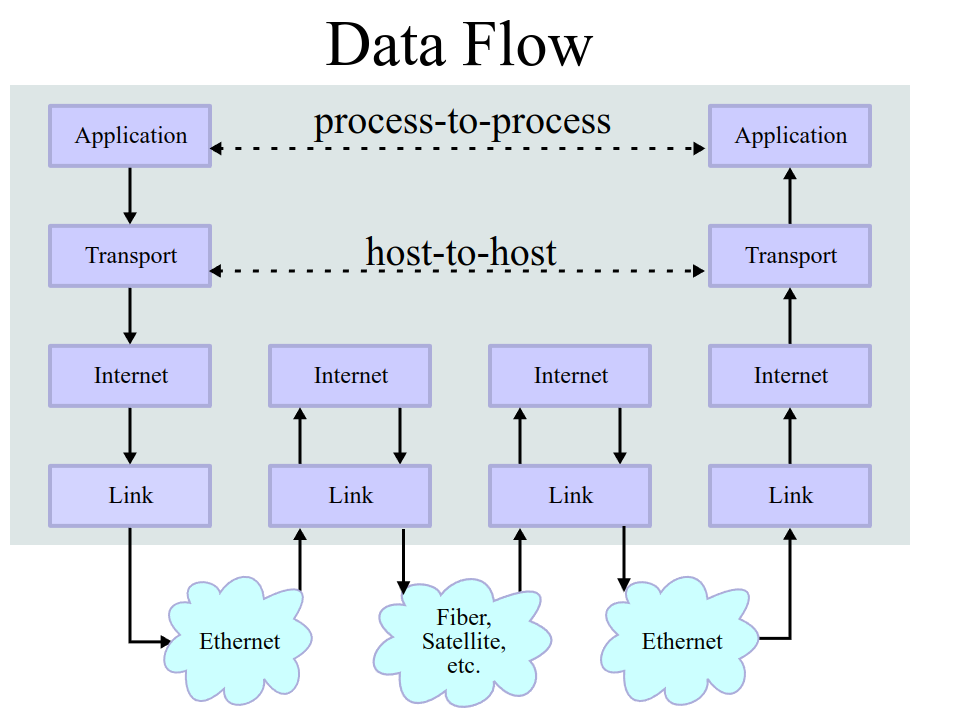
As we can see, the communication that happens between two applications needs to use a series of abstraction. We can think about these layers of abstraction in two different ways: top-to-bottom, or bottom-to-top.
Going from top to bottom, the first abstraction we need is the one
that grants process-to-process communication. The network layer
that creates this abstraction is called the transport layer. Common
transport layer protocols are UDP and TCP. Then we need the
host-to-host communication abstraction. The network layer that has
this responsibility is called the internet layer, and a common
protocol implemented for this layer is the IPv4 protocol. We could
continue to describe the other layers, but that is not the point of
this blog post. What we are interested in is the following
With respect to the standard ISO/OSI model, the TLS protocol operates between the session and presentation layer. Historically, when the first internet protocols such as ARP, IP, TCP, UDP, HTTP, FTP and DNS were designed, the focus was on making them work, not on making them secure or privacy-preserving. It was only years later, when the world was a completely different place – drastically changed by the possibilities offered by digital communications – that the need for security was felt. The TLS protocol arises to meet these new demands. To achieve this, TLS combines many well-studied cryptographic primitives in a complex network protocol made up of various sub-protocols, message types, possible configurations and extensions. Said in simpler words
Now, the word "security" is a very ambigious word and should be used with great care. While it is ok as a starting point, it quickly becomes pretty much useless if not explained further. What do we mean with "security purposes"? To paint a clear picture, let us visualize what would happen if we remove the TLS protocol from the internet of today.
#A World without TLS
In a world without TLS, to interact with a web server we would not have HTTPs, but only plain old HTTP. When a client connects to a server using plain HTTP, first a TCP channel is created between the client and the server, and then the HTTP application data is sent on the created channel. The TCP protocol however has no notion of cryptography built into it, which means that given a sufficiently motivated attacker with enough resources many things can go wrong. We will not describe some of them.
For starters, an attacker can directly see all the data by tapping into the network where the packets are being transfered. If we consider for a moment that the internet is a decentralized network of networks, all our packets, independently from where they start off, end up in networks we have no control over, managed by people we have no business with. I wouldn't trust an internet where all my data is sent in clear. In these situation we say that the protocol lacks confidentiality.
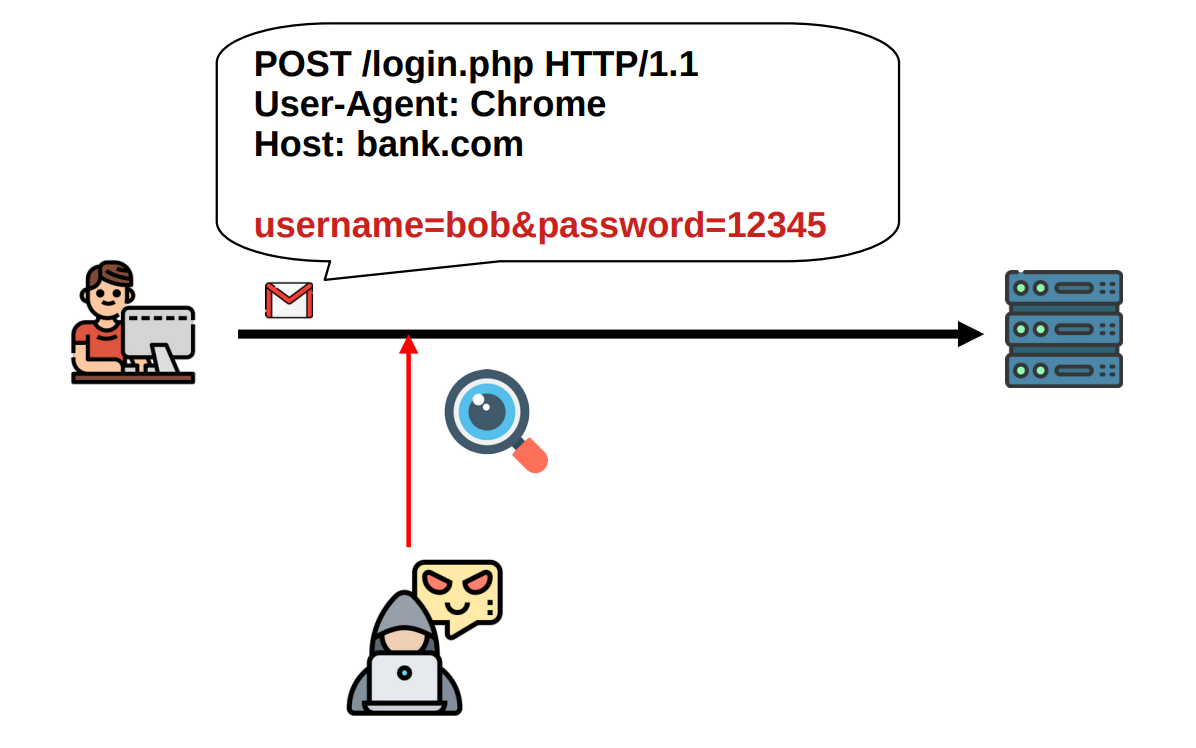
Another thing that can go wrong is that an attacker can change the data being sent from the client to the server, or vice-versa, the attacker can change the data that the server sends back to the client. In both of these cases, the one who receives the data has no mechanism to detect that something has been changed with malicious intentions. Depending on the activity in question, this could lead to dangerous situations. What, for example, if the site was a banking site, and the data changed by the attacker was the destination of the money transfer requested by the client? It is not hard to imagine the disastrous consequences of such possibility. In technical terms, this situation is referred to as a lack of integrity.
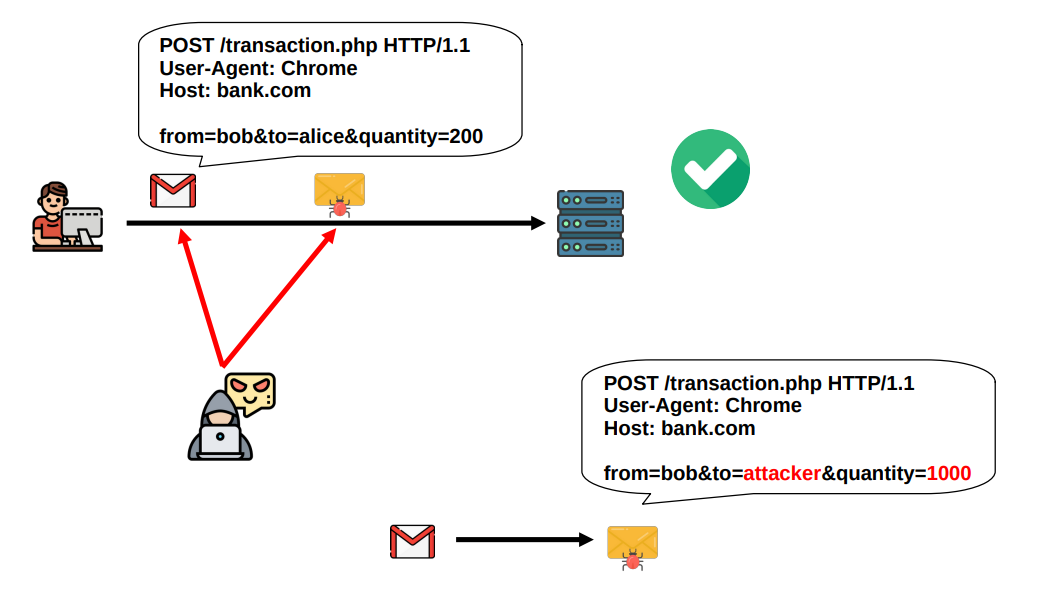
Continuing, an attacker can pretend to be someone he/she is not. In particuar, the attacker can fake to be a certain server, and the client has no idea if on the other end of the established TCP channel lies the legitimate server, or an impostor trying, for example, to steal the client’s sensitive login data. The same situation can happen in reverse, where its the server that does not know whether the client that just requested a connection is a legitimate client or if its an impostor trying to execute an impersonation attack. Depending on the application in question both cases could be dangerous and we should at least have a choice of whether or not we want to avoid such situations. In technical terms, this situation is referred to as a lack of authentication.
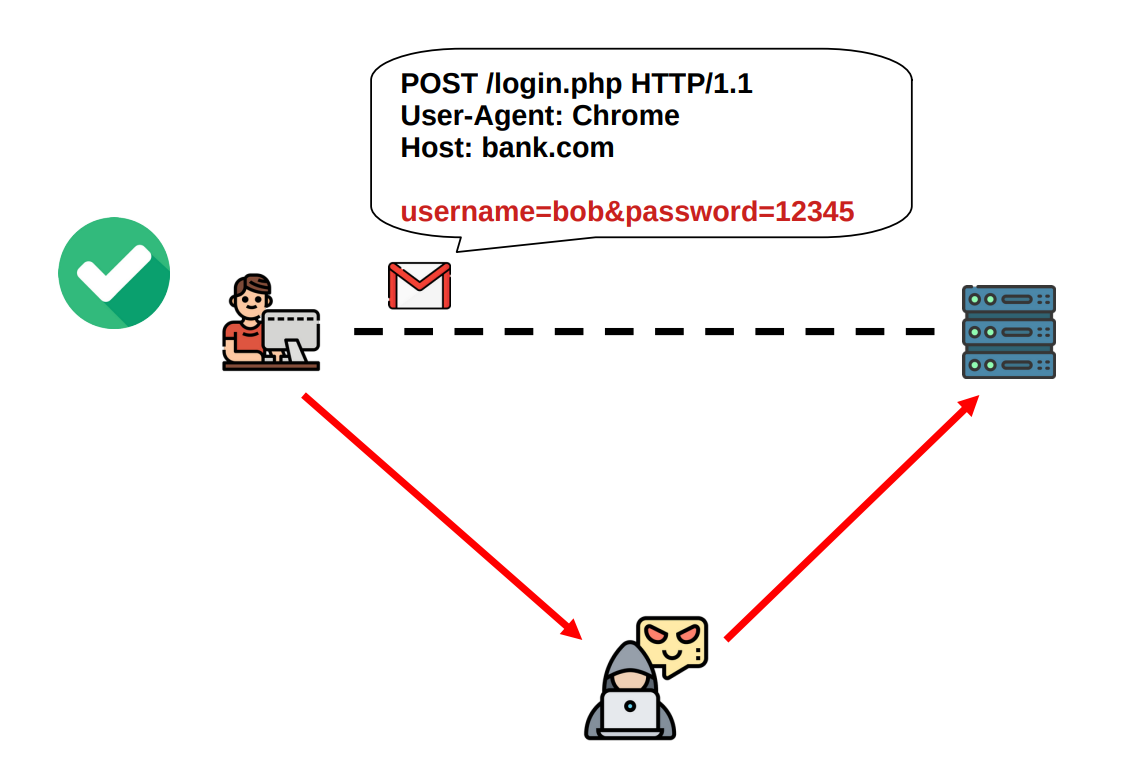
To recap, there are mainly three different things that can go wrong with plain old HTTP/TCP:
-
Lack of confidentiality: An attacker can see all the data that is being transfered.
-
Lack of integrity: An attacker can change the data according to its own needs.
-
Lack of authentication: An attacker can pretend to be anyone.
Would you want an internet where this is possible? I don’t think so. Thankfully, the internet we have today is not like this, because in the internet we have today have TLS.
#A world with TLS
The ultimate objective of the TLS protocol is to guarantee that none of the previous scenarios can happen. To achieve this result, TLS incorporates the usage of strong cryptographic primitives. The most important security guarantees that TLS is designed to obtain are the following:
-
Confidentiality: An attacker should not be able to see the data being sent between the client and the server
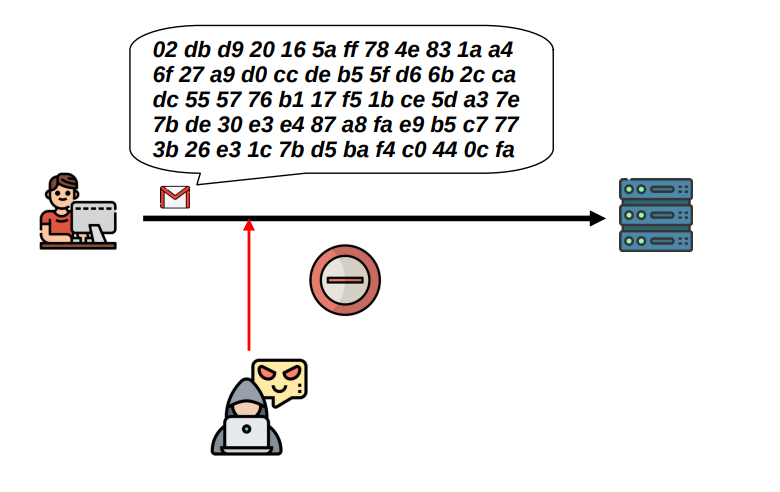
We have confidentiality when data, objects and resources are protected from unauthorized viewing and other access.
-
Integrity: An attacker should not be able to modify the data in transit without being recognized by whoever is the receiver of such data. He can still try, but he will be caught immediately.
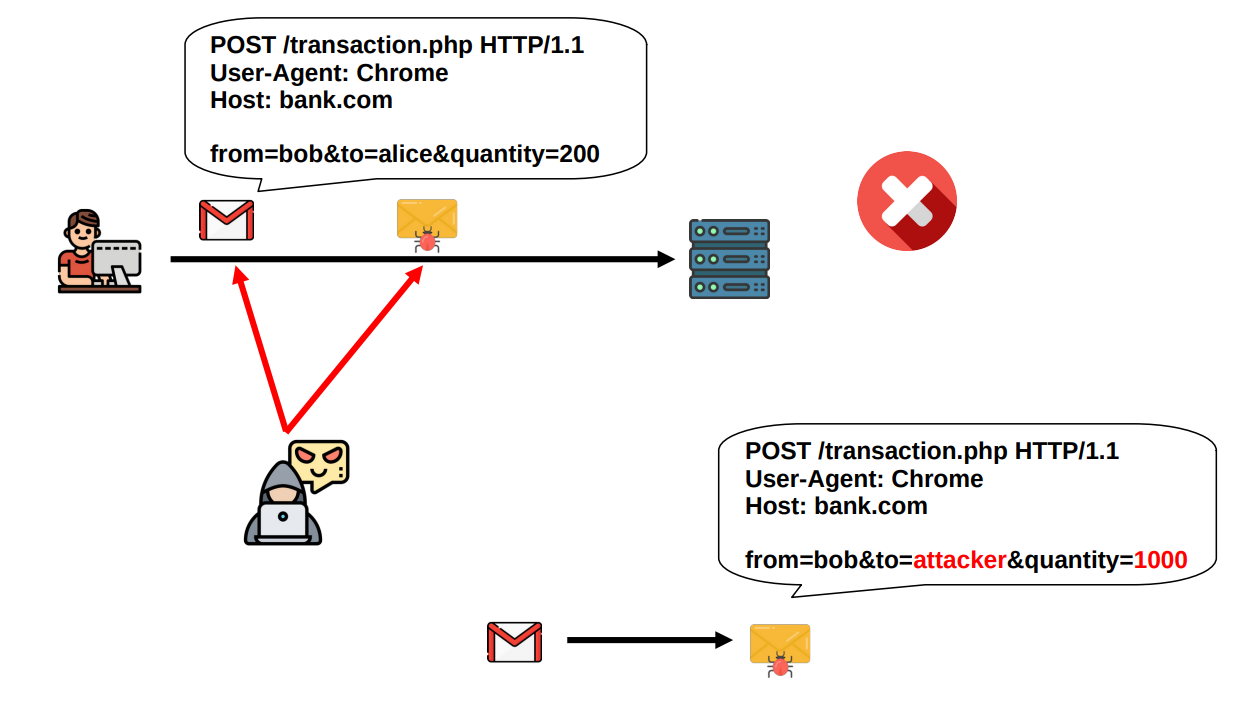
We have integrity when data is protected from unauthorized changes to ensure that it is reliable and correct.
-
Authentication: An attacker should not be able to impersonate anyone.
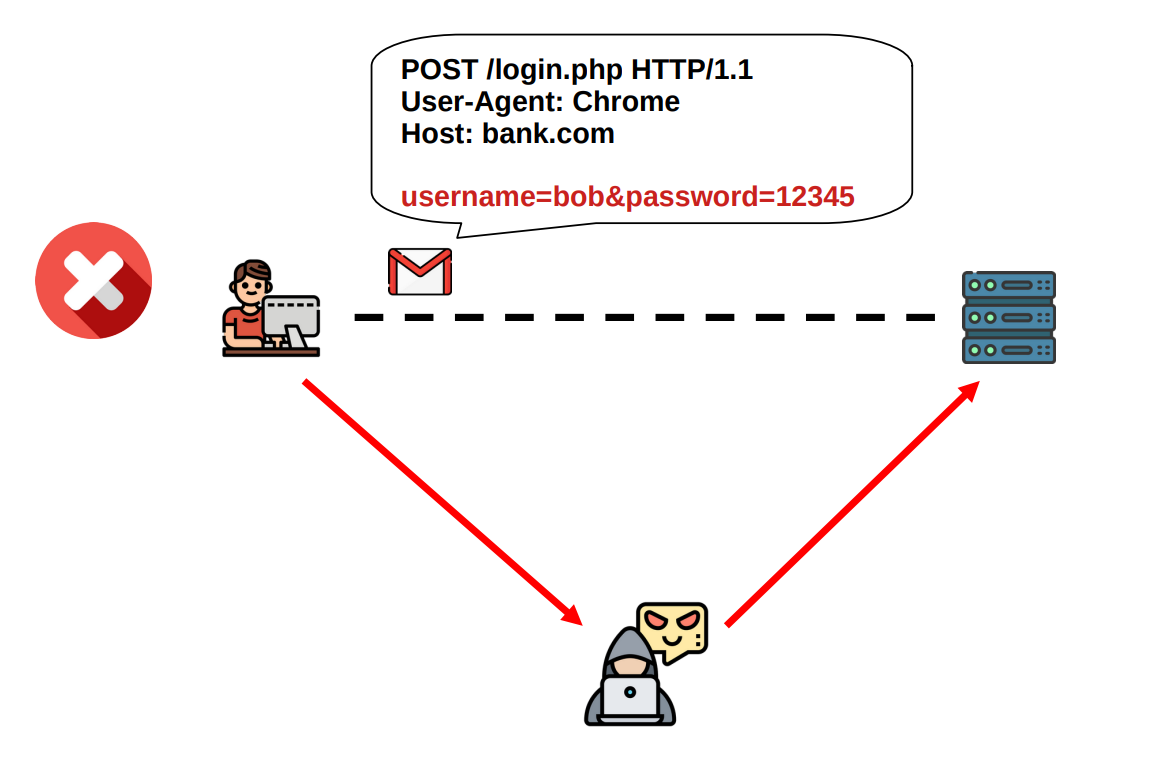
We have authentication when you can verify if the entity you're connecting to is a legitimate entity or not.
Going back to our initial example, if we now include TLS in the communication between client and server, we get HTTPs, which essentially means “HTTP over a TLS channel”. When a client first connects to a web server using HTTPs, a TCP channel is created between the two endpoints. Then, both parties perform a TLS handshake by sending each others specific TLS messages, and at the end of the handshake a TLS channel as well as a TLS session is set up between client and server. This channel has all the cryptographic properties mentioned before, and can therefore be considered a secure channel. After the session has been established, the application data is sent through the TLS channel, inheriting all the security properties of the channel itself.

So far I have just mentioned the single acronym "TLS". Historically however TLS was first known as SSL, another acryonim which stands for "Secure Socket Layer". In 1999 SSL was standardized by the IETF, which is the main organization responsible for developing the standars of the internet by publishing various RFCs. During this standardization, a sort of rebranding happened, and the name SSL was changed to TLS.
The first version of the SSL protocol appeard in 1995 as SSLv2. It was developed by the company behind the Netscape browser and was found to have multiple cryptographic vulnerabilities and weak points in its design. Then, in the years since, new versions were introduced and standardized, starting with SSLv3 in 1996 and ending up with TLSv1.3, the latest version, officially standardized around 2018.
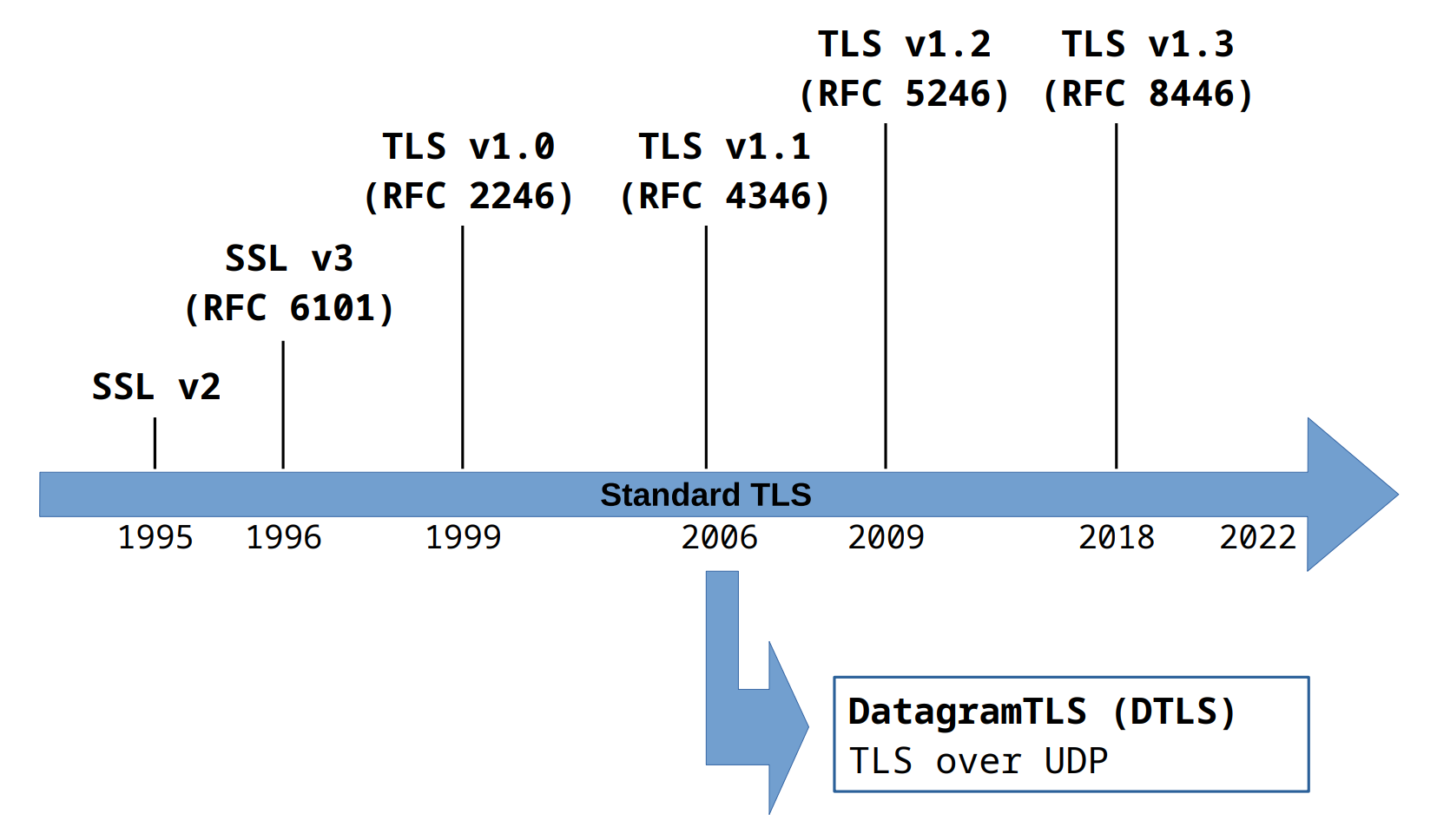
Nowadys the SSL/TLS ecosystem is extremely complex, not only because there are multiple standardized versions, but also because of the existence of various implementations of those protocols. Some of these implementations are open-source, while some others are proprietary software used within specific organizations. Historically the most famous open-source implementation of SSL/TLS is OpenSSL. Some other open-source implementations are listed below:
- BoringSSL
- BouncyCastle
- Botan
- OpenSSL
- GnuTLS
- Java Secure Socket Extension (JSSE)
- LibreSSL
- MatrixSSL
- Mbde TLS
- WolfSSL
There are a multitude of aspects to look at when analyzing the inner workings of the TLS protocol, and in the years since its first inception many vulnerabilities and unindented aspects of the protocol have been discovered over the various implementations. Some of these vulnerabilities, if exploited under certain assumptions, could break a subset of the cryptographic guarantees of the protocol. To understand these attacks however we need to understand the basic ideas behind TLS, which will be the topic of this last section.
#Getting to know TLS
Out of all the tools and primitives that came as a result of cryptographic research, so far two cryptographic methods in particular – that is, two ways of dealing with cryptographic keys and procedures for encryption and decryption – stand out. These are:
-
Symmetric encryption, the oldest of the two, in which entities that want to communicate in a secure way have to use the same encryption key.
-
Asymmetric encryption, where each entity involved in the communication has two particular keys, a private key and a public key. Messages encrypted with one of the keys can be decrypted only with the other one, and from the private key it is easy to get back the public key, but from the public key one cannot easily get back the private key.
Consider we have two individuals \(A\) and \(B\), that want to communicate with each other so that no one but them can see the actual contents of the messages. That is, they want the communication to have the property of confidentiality. While in the symmetric world these two individuals would have to somehow share the same symmetric key \(k\) before actually communicating – a very strong assumption to make, that depending on the situation could be very hard to satisfy – in the asymmetric world this assumption is no longer needed, because, for example, the first individual, \(A\), has its own pair of keys (\(A_{\text{private}}\) , \(A_{\text{public}}\)), and whenever \(B\) wants to send a message \(m\) to \(A\), he/she can just use the public key \(A_{\text{public}}\) to encrypt the message \(m\), obtaining the ciphertext \(c\)
\[c = \text{Encrypt}(A_{\text{public}} \;\;,\;\; m)\]
and only \(A\), with its private key \(A_{\text{private}}\), can decrypt it to recover the original message \(m\).
\[m = \text{Decrypt}(A_{\text{private}} \;\;,\;\; c)\]
The point to understand here is that asymmetric cryptography enabled for the first time in the history of cryptography two entities that have never interacted before or met in other ways to still establish a secure cryptographic channel. This property allows for the creation of extremely large cryptographic systems made up of all sorts of entities. Where is the catch here? If asymmetric encryption allows this very powerful sort of scalability, does it even make sense to still use symmetric encryption? Yes, it actually does, and the reason is simple: efficiency.
While asymmetric cryptography is very scalable with respect to the number of peers that can join the system and interact safely with each other, it is not very efficient with respect to the encryption and decryption computations as well as the key generation process. That is, if we compare these computational processes, we find that
To have scalable systems both in terms of number of peers as well as in the computational processes, the idea is to combine symmetric and asymmetric cryptography. Asymmetric cryptography is used as a starting point to share, securely, a symmetric key between the entities that have possibly never met. Then, symmetric cryptography kicks in, and the entities involved in the communication use the same symmetric key previously generated and shared to encrypt and decrypt messages. This is exactly the main idea behind the design of SSL/TLS.
In TLS the first thing that happens when a clients connect to a server with the intent of establishing a TLS session is the exchange of a first series of messages which, taken together, form the TLS Handshake. In this handshake client and server come to an agreement with respect to the particular cryptography to use for the rest of the communication. In particular they decide:
-
What kind of public cryptography to use for the key exchange process. This is the process which is used to set up an initial symmetric key starting from scratch.
-
What kind of public cryptography to use for the authentication process. This is where the server authenticates to the client, that is, the client understands exactly the identity of the server at the end of the communication. And since TLS allows for mutual authentication, in this process the server can also choose to authenticate the client.
-
What kind of symmetric cryptography to use for granting confidentiality and integrity to the data exchanged within the TLS channel during the communication.
After having decided all of this, they proceed with the actual processes of key exchange and authentication. These two processes are critical for the safety of the TLS session that is being established. While for the key exchange process there are various robust algorithms based on mathematics, such as the Diffie-Hellman Key Exchange, or the RSA Key Exchange, authentication is instead a tricky and complex concept in and of itself.
There are many different ways in which parties can establish trust in a system, and many more are being researched right now. To deal with authentication TLS uses a centralized hierarchical structure through the usage of PKI, acryonim for "Public Key Infrastructure". The PKI is external to the TLS protocol itself, its not based on mathematics, and therefore it is one of the weakest aspect of the protocol. The PKI can be abstracted as an external system that allows for the generation, verification and revocation of cryptographic certificates. A certificate can be thought of as a special contract, who's role is to bind a particular public key – typically just a number, or, more generally, a mathematical object such as an element in an algebraic structure – to the name of an entity in the external system in which the TLS protocol is used. While the PKI can be a great addition to the security of the web, it is not a bulletproof solution, and many ways to bypass it have been found over the years, both technically, due to implementation bugs and other errors, and socially, with simple but effective phishing techniques.
Another key idea implemented in the design of TLS is that of choice and flexibility. The idea of having more choices is, somehow, always appealing to the humand mind. We always want more choices, not less choices. Maybe it is because we implicitly assume that more choices means more possibilities, and that out of those possibilities, given that they are very vast and cover a lot of ground, we will able to pick the better one, the one that fits exactly our needs. The problem with this line of thought is that it does not take into account that to deal with many possibilities one needs a sufficient amount of processing power. During the design of early versions of TLS it was thought that it was not a good idea to rely on specific cryptographic implementations, because in time someone might discover a structural weakness on the implementations used, or, more simply, as the hardware and software become more efficient, brute-force attacks inevitably also become stronger. The idea therefore was to have a protocol which allows to plug-in or plug-out specific cryptographic implementations. The concept of flexibility is implemented in TLS with two mechanisms in particular:
-
Cipher suites: where each cipher suite represents a specific set of cryptographic algorithms to use for the TLS session. During the TLS handshake client and server agree on which cipher suite to use.
-
Extensions: which are also agreed upon the start of a TLS session during the TLS handshake and can be used in various ways to define new TLS message types, or to exchange extra cryptographic parameters such as elliptic curves and signature algorithms supported.
While initially this was thought to be only a positive addition to the protocol, it is important to consider the problem of complexity, one that too often was not addressed enough by sophisticated protocols such as TLS. Over the years various cipher suites configurations were added, and various others were discouraged to use after the discovery of structural weaknesses on them. This slowly led to the design of TLS v1.3, the latest version of TLS up to date. TLS v1.3 drastically simplified the managing of cipher suites and extensions and it inverted the trend: instead of giving more, for the first time choices were removed, things were simplified, and the few possibilities that were left are extremely solid cryptography primitives that so far no one has shown to be able to break, such as Authenticated Encryption (EA) schemes.
As a final recap, we have said that the TLS protocol has two main phases. In the first phase, called the TLS handshake, client and server agree on which cryptographic algorithms to use, and then proceed to authenticate themselves, if they wish to do so, with the help of asymmetric cryptography and an external system called PKI, who’s role is to generate, validate and revocate client and server certificates. After the authentication step is done, the parties use once again asymmetric cryptographic to construct and share with each other a symmetric key. After the key is shared, the TLS handshake phase is done, and the protected TLS session starts. During this session messages sent in the TLS channel are proteted with respect to confidentiality and integrity by using the symmetric key generated during the handshake and the algorithms choosen during the handshake.
This is it, for this initial introduction to TLS. I hope it was interesting to read, and in the next posts I will look in depth at various aspects of the protocol.